Intelligence artificielle et Machine Learning: méthodes, algorithmes et applications






Leçon 28: Linear Discriminant Analysis LDA: Réduction de dimension supervisée
Toutes les leçons 
Intelligence artificielle et Machine Learning: méthodes, algorithmes et applications
Leçon 14
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
Leçon 28
Linear Discriminant Analysis LDA: Réduction de dimension supervisée
Linear Discriminant Analysis LDA: Réduction de dimension supervisée
LDA: une réduction supervisée pour mieux séparer les classes
PCA vs LDA: variance globale ou séparabilité des groupes?
La LDA (Linear Discriminant Analysis) est une méthode statistique de réduction de dimension supervisée. Contrairement à la PCA (Principal Component Analysis), qui ignore les étiquettes des données, LDA utilise les classes connues pour trouver des axes qui maximisent la séparation entre elles. L’idée est de projeter les données dans un espace de plus faible dimension tout en conservant la meilleure discriminabilité possible entre les groupes. En pratique, LDA calcule des directions qui maximisent le rapport entre la variance inter-classes et la variance intra-classes, ce qui en fait un outil puissant pour la classification et la visualisation de données étiquetées.La différence fondamentale avec la PCA (Principal Component Analysis) réside dans l’objectif. En effet:
- PCA: cherche à capturer la variance globale des données sans se soucier des classes, ce qui en fait l'outil idéal pour explorer et visualiser des données complexes de manière non supervisée.
- LDA: cherche à optimiser la séparation entre classes, donc plus adaptée aux contextes supervisés où l’on dispose de labels et où l’on veut améliorer la performance d’un classificateur.
En résumé, PCA est une technique de compression d’information basée sur la variance, tandis que LDA est une technique de séparation supervisée basée sur les classes. Sur des jeux de données comme Iris, PCA permet de voir la structure générale, mais LDA met en évidence les frontières entre espèces, ce qui illustre bien leur complémentarité.
LDA appliquée au dataset Iris: réduction de dimension et visualisation
Dans le cas du dataset Iris, on dispose de 4 variables (longueur et largeur des sépales et pétales), ce qui rend leur visualisation simultanée difficile. L’Analyse Discriminante Linéaire (LDA) permet de projeter ces données dans un espace de dimension réduite en exploitant les étiquettes des classes. L’objectif est de trouver des axes qui maximisent la séparation entre les différentes espèces d’Iris, en cherchant à réduire la variance intra‑classe tout en augmentant la variance inter‑classe.Je propose ce code:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
iris = load_iris()
X = iris.data
y = iris.target
# Normalisation des données
X_scaled = StandardScaler().fit_transform(X)
# Appliquer LDA (réduction à 2 dimensions)
lda = LDA(n_components=2)
X_lda = lda.fit_transform(X_scaled, y)
# Visualiser les données projetées
plt.figure(figsize=(8,6))
for target in np.unique(y):
plt.scatter(
X_lda[y == target, 0],
X_lda[y == target, 1],
label=iris.target_names[target]
)
plt.xlabel("Composante LDA 1")
plt.ylabel("Composante LDA 2")
plt.title("Projection LDA du dataset Iris")
plt.legend()
plt.show()
# Afficher la variance expliquée par chaque axe discriminant
print("Variance expliquée :", lda.explained_variance_ratio_)
La logique utilisée pour la PCA reste globalement la même: on charge le dataset Iris, on normalise les données, puis on applique une méthode de réduction de dimension avant de visualiser les résultats.
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
iris = load_iris()
X = iris.data
y = iris.target
# Normalisation des données
X_scaled = StandardScaler().fit_transform(X)
# Appliquer LDA (réduction à 2 dimensions)
lda = LDA(n_components=2)
X_lda = lda.fit_transform(X_scaled, y)
# Visualiser les données projetées
plt.figure(figsize=(8,6))
for target in np.unique(y):
plt.scatter(
X_lda[y == target, 0],
X_lda[y == target, 1],
label=iris.target_names[target]
)
plt.xlabel("Composante LDA 1")
plt.ylabel("Composante LDA 2")
plt.title("Projection LDA du dataset Iris")
plt.legend()
plt.show()
# Afficher la variance expliquée par chaque axe discriminant
print("Variance expliquée :", lda.explained_variance_ratio_)
La différence essentielle vient de l’algorithme choisi. Avec la PCA, on utilise PCA(n_components=2) et on projette les données en cherchant les axes qui capturent le maximum de variance. Avec la LDA, on remplace simplement par LDA(n_components=2) et on appelle fit_transform(X_scaled, y) au lieu de fit_transform(X_scaled).
Ce changement est crucial car la PCA ne tient pas compte des labels (y), alors que la LDA en a besoin pour calculer les directions discriminantes. Dans le code, cela se traduit par l’ajout de y comme argument lors de l’entraînement du modèle. Enfin, l’interprétation change aussi: les axes obtenus ne représentent plus la variance globale des données, mais les combinaisons linéaires de variables qui maximisent la séparation entre les classes d’Iris.
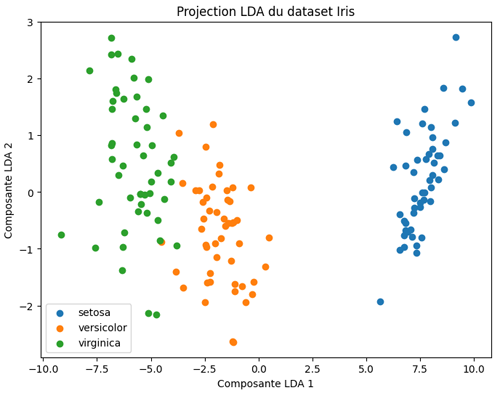
La différence avec PCA vient du fait que la LDA exploite les étiquettes des classes. Les axes obtenus, appelés composantes discriminantes, ne représentent pas simplement la variance maximale des données, mais les directions qui maximisent la séparation entre les espèces d’Iris.
- Composante LDA 1: c’est l’axe qui capture la meilleure discrimination entre les classes. Il combine linéairement les quatre variables (longueur/largeur sépales et pétales) de manière à séparer au maximum les espèces.
- Composante LDA 2: c’est l’axe complémentaire, qui ajoute une deuxième dimension discriminante pour affiner la séparation.
Ainsi, contrairement à la PCA qui cherche uniquement à condenser l’information en fonction de la variance, la LDA projette les données dans un espace où les frontières entre classes sont plus nettes, ce qui facilite la classification et la visualisation supervisée.
On affiche également la proportion de variance discriminante capturée par chaque composante de la LDA, ce qui indique dans quelle mesure chaque axe contribue à séparer les classes.
Variance expliquée : [0.9912126 0.0087874]
La valeur Variance expliquée en LDA indique la proportion de la capacité discriminante capturée par chaque axe. En effet, avec la LDA, les axes obtenus ne reflètent pas la variance maximale des données mais la capacité discriminante entre les classes. Dans ce cas, la première composante LDA concentre environ 99,1% de l’information discriminante, ce qui signifie qu’elle suffit presque à elle seule pour séparer les espèces d’Iris. La deuxième composante, qui n’explique qu’environ 0,9%, joue un rôle secondaire et n’apporte qu’un complément marginal.
En pratique, cela montre que la LDA réussit à condenser la séparation entre classes principalement sur un seul axe, rendant la visualisation et la classification particulièrement efficaces.
Leçon 14
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
Leçon 28
Linear Discriminant Analysis LDA: Réduction de dimension supervisée
Linear Discriminant Analysis LDA: Réduction de dimension supervisée

