Intelligence artificielle et Machine Learning: algorithmes et applications






Leçon 6: Apprentissage supervisé - La classification
Toutes les leçons 
Intelligence artificielle et Machine Learning: algorithmes et applications
Leçon 6
Apprentissage supervisé - La classification
Apprentissage supervisé - La classification
La classification - Prédire les catégories à partir de données
En quoi consiste la classification dans l'apprentissage supervise?
La classification est l’un des piliers de l’apprentissage supervisé. Elle consiste à prédire une variable dépendante qualitative, aussi appelée variable catégorielle, à partir d’un ensemble de variables indépendantes (ou explicatives). Contrairement à la régression qui cherche à estimer une valeur numérique continue, la classification vise à attribuer chaque observation à une classe prédéfinie.Ces classes peuvent être :
- Binaires: comme dans le cas du tri d’emails entre "spam" et "non spam", ou la détection de fraude ("fraude" vs "légitime").
- Multiclasse: comme le type de fleurs d'Iris (Setosa, Versicolor, Virginica), le genre d’un film (comédie, drame, action), ou le chiffre manuscrit reconnu par une caméra (de 0 à 9).
Les fleurs d'Iris font l'objet d'un dataset très célèbre en apprentissage supervisé. Il contient des mesures de fleurs appartenant à trois espèces (Setosa, Versicolor, Virginica) et constitue un cas d’école pour les algorithmes de classification. Nous aurons l'occasion de le traiter à l'aide d'algorithmes de classification plus loin dans ce cours.
Dans l'approche de classification, le modèle apprend à identifier des motifs discriminants dans les données d’entrée, c’est-à-dire des combinaisons de caractéristiques qui permettent de différencier les classes. Par exemple, à partir de mesures comme la longueur des pétales, la largeur des sépales ou la couleur, un algorithme peut prédire à quelle espèce appartient une plante du genre Iris. De même, en analysant les pixels d’une image, un modèle peut reconnaître s’il s’agit du chiffre 3 ou 7 par exemple.
La classification est omniprésente dans les applications réelles. D'ailleurs, elle est même plus utilisée que la régression. A titre d'exemple, la classification peut être utilisée dans les domaines de:
- La santé: pour diagnostiquer une maladie à partir de symptômes ou d’images médicales.
- La sécurité: pour identifier des visages ou détecter des comportements suspects.
- Le marketing: pour segmenter les clients selon leurs préférences ou comportements.
- Le traitement du langage naturel (NLP): pour analyser le sentiment véhiculé à travers un texte (positif, négatif, neutre).
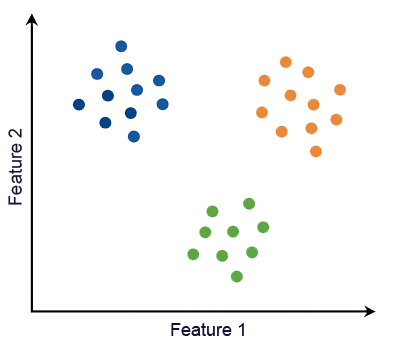
Cette illustration représente un nuage de points segmentés en 3 classes par le modèle (classification multiclasse) :
Algorithmes de classification emblématiques
Il existe un grand nombre d'algorithmes de classification, entre autres:- Régression logistique: Malgré son nom, il s’agit bien d’un algorithme de classification. Il modélise la probabilité d’appartenance à une classe à l’aide d’une fonction logistique (sigmoïde). Très utilisé pour les problèmes binaires.
- Arbre de décision (Decision Tree Classifier): Cet algorithme divise l’espace des variables en régions homogènes selon des règles simples. Ses résultats sont interprétables mais il est sensible au sur-apprentissage (overfitting).
- Random Forest Classifier: Ensemble d’arbres de décision entraînés sur des sous-échantillons (on parle dans ce cas de modèle ensembliste). Il s'agit d'un modèle robuste et moins sensible au bruit.
- k-Nearest Neighbors (k-NN): Cet algorithme classe une observation selon la majorité des k plus proches voisins. Il est simple, mais sensible à la dimension et au bruit.
- Support Vector Machine (SVM): Cet algorithme cherche à maximiser la marge entre les classes. Il peut modéliser des frontières non linéaires grâce à "l'astuce du noyaux" (kernel trick).
- Naive Bayes: Il est basé sur le théorème de Bayes avec une hypothèse d’indépendance entre les variables. Il est rapide et (surtout pour le traitement de données textuelles).
Il existe plein d'autres algorithmes et variantes d'algorithmes qui permettent de mener des tâches de classification. Nous aurons l'occasion d'en découvrir quelques uns quand on sera entré à fond dans la classification.
Les meilleurs modèles de classifications sont sans aucun doute basés sur les réseaux de neurones (Deep Learning), mais ce cours est consacré spécialement au Machine Learning. Un cours de Deep Learning est programmé séparément.
Métriques de performances pour évaluer la qualité d'un modèle de classification
En classification, évaluer la qualité d’un modèle ne se limite pas à vérifier s’il prédit juste. Il faut comprendre comment il se trompe, dans quelles proportions et pour quelles classes. C’est pourquoi on utilise plusieurs métriques complémentaires, chacune mettant en lumière un aspect spécifique de la performance. Ces métriques s’appuient souvent sur la matrice de confusion, qui distingue les vrais positifs (VP), faux positifs (FP), vrais négatifs (VN) et faux négatifs (FN).Les principales métriques de performances en classification sont:
- Exactitude (Accuracy): Elle indique la proportion globale de prédictions correctes, mais il est peu fiable en cas de classes déséquilibrées, c'est à dire des classes qui ne sont pas réparties uniformément dans le dataset.
- Précision: Elle indique combien d'éléments sont réellement positifs parmi les éléments prédits comme positifs. C'est une métrique utile quand les faux positifs sont coûteux (comme par exemple diagnostic médical erroné).
- Rappel (Recall ou sensibilité): Cette métrique essaie de répondre à cette question "Parmi les vrais positifs, combien ont été correctement identifiés?". Elle est utile quand les faux négatifs sont critiques (exemple: détection de fraude).
- Score F1: Il s'agit d'une moyenne harmonique entre précision et rappel, donc elle essaie d'englober en même temps ces deux métriques. En effet, elle équilibre entre les deux métriques, ce qui est surtout utile en cas de classes déséquilibrées.
Voilà les formules de calcul de ces métriques de performances:
\(Accuracy = \frac{TP + TN}{TP + TN + FP + FN}\)
\(Precision= \frac{TP}{TP + FP}\)
\(Recall= \frac{TP}{TP + FN}\)
\(F_1 = 2 \cdot \frac{Précision \cdot Rappel}{Précision + Rappel}\)
Il existe également des illustrations qui montrent ces métriques de manière plus précises comme la matrice de confusion (confusion matrix), la courbe ROC (Receiver Operating Characteristic) et AUC (Area Under Curve).
Leçon 6
Apprentissage supervisé - La classification
Apprentissage supervisé - La classification


