Intelligence artificielle et Machine Learning: algorithmes et applications






Leçon 1: Intelligence artificielle: Définition, histoire et évolution
Toutes les leçons 
Intelligence artificielle et Machine Learning: algorithmes et applications
Leçon 1
Intelligence artificielle: Définition, histoire et évolution
Intelligence artificielle: Définition, histoire et évolution
Intelligence artificielle - Histoire et définition
Histoire de l'intelligence artificielle
L’intelligence artificielle (IA) est née d'une idée ancienne qui consiste à créer des machines capables de penser comme des humains. Dès l’Antiquité, des mythes évoquaient des automates dotés d’intelligence, mais c’est au XXe siècle que l’idée prend forme scientifique. En 1950, le célèbre mathématiciens Alan Turing propose le célèbre test de Turing pour évaluer la capacité d’une machine à imiter l’intelligence humaine. Puis, en 1956, lors de la conférence de Dartmouth, le terme "intelligence artificielle" est officiellement introduit par John McCarthy en marquant la naissance de l’IA comme discipline académique.Le prix Turing, considéré comme le "prix Nobel de l’informatique", a été créé en hommage à Alan Turing, pionnier de l’intelligence artificielle et de la science informatique.
Dans les années 1960 et 1970, les premiers programmes capables de résoudre des problèmes logiques ou jouer aux échecs ont vu le jour et on réveillé la flame liée à l'IA après des décennies de désengagement. Cependant, les limites technologiques freinent les avancées. En effet, les algorithmes liés à l'IA demandaient des ressources matérielles qui n'étaient pas disponibles à l'époque, sans parler de la quantité astronomique de données qu'il faut avoir à disposition pour entrainer les modèles IA. Un regain d’intérêt survient dans les années 1980 avec les systèmes experts capables de simuler le raisonnement humain dans des domaines spécifiques. Toutefois, leur rigidité conduit à un second hiver de l’IA notamment à la fin des années 80.
Depuis les années 2000, l’IA connaît une renaissance spectaculaire grâce au Big Data, à la puissance de calcul et aux progrès en Machine Learning. Les algorithmes d’apprentissage automatique permettent aux machines d’analyser des données massives, de reconnaître des images, de traduire des langues ou de prédire des comportements. L’émergence du Deep Learning dans les années 2010, avec des réseaux de neurones profonds, propulse l’IA dans des applications grand public comme les assistants vocaux, les voitures autonomes, la médecine prédictive… L’histoire de l’IA est ainsi celle d’une quête continue pour simuler l’intelligence humaine, avec des avancées majeures et des défis éthiques toujours plus complexes.
Des modèles comme AlphaGo (2016) ou GPT (depuis 2018) illustrent cette montée en puissance, capables de battre des champions ou de générer du texte avec une fluidité impressionnante. L’arrivée de ChatGPT en 2022 démocratise l’IA générative, ouvrant la voie à des usages créatifs, éducatifs et professionnels à grande échelle. Cette période marque un tournant. En effet, l’IA devient un outil quotidien tout en soulevant des enjeux éthiques majeurs liés à la transparence, aux biais et à la régulation.
Mais, qu'est ce que l'intelligence artificielle d'abord?
L’intelligence artificielle (IA) désigne l’ensemble des techniques permettant à une machine de simuler des comportements intelligents, c’est-à-dire de percevoir, raisonner, apprendre et agir en fonction d’un objectif.Contrairement à la programmation classique (nommée aussi parfois programmation explicite ou déterministe) où chaque étape est codée explicitement par un humain, l’IA repose sur des modèles capables de généraliser à partir de données. C'est à dire que le modèle pourra résoudre un problème en apprenant à partir des exemples sur lesquels il a été entrainé. Pour faire simple, on ne dit plus à la machine quoi faire, mais comment apprendre à le faire.
Grâce à des algorithmes d’apprentissage automatique (Machine Learning), elle peut résoudre des problèmes complexes comme la reconnaissance d'une image, la traduction d'un texte ou la prédiction d'une tendance sans que chaque règle ne soit définie à l’avance. Cette approche transforme radicalement notre rapport à la programmation (on entraîne la machine plutôt que de la diriger ligne par ligne).
Rapport entre l'intelligence artificielle, le Machine Learning et le Deep Learning
Machine Learning (apprentissage automatique)
L’intelligence artificielle est un domaine vaste qui regroupe toutes les techniques visant à simuler des comportements intelligents chez les machines. Elle englobe des systèmes capables de percevoir leur environnement, de prendre des décisions, d’apprendre et d’interagir. L’IA peut être basée sur des règles explicites (comme c'est le cas des systèmes experts), mais elle s’appuie de plus en plus sur des approches statistiques comme le Machine Learning.Le Machine Learning est une branche de l’intelligence artificielle qui consiste à concevoir des algorithmes capables d’apprendre à partir de données, sans être explicitement programmés pour chaque tâche. Plutôt que de coder manuellement des règles pour résoudre un problème, on fournit à la machine un ensemble d’exemples (on parle de données d'entrainement). A partir de ces exemples, elle apprend à généraliser et à faire des prédictions ou des décisions sur des nouvelles données (qu'elle n'a pas forcément vu lors de son entrainement).
L’apprentissage en Machine Learning peut être supervisé, non supervisé ou par renforcement. Je ne vais pas détailler ces concepts pour le moment car on va les voir en détail dans la leçon sur les types d'apprentissages.
Le Machine Learning repose sur des modèles statistiques et mathématiques et son efficacité dépend fortement de la qualité des données et du choix des algorithmes implémentés dans le modèle.
Deep Learning (apprentissage profond)
Le Deep Learning est une sous-branche du Machine Learning qui utilise des réseaux de neurones artificiels profonds (d'où l'expression Deep) pour traiter des données complexes. Le Deep Learning apprend à extraire les représentations pertinentes à partir des données brutes et complexes comme des images ou du texte. Cette approche a permis des avancées majeures dans la reconnaissance vocale, la vision par ordinateur et les modèles de langage comme GPT.En résumé, l'intelligence artificielle est le cadre général, le Machine Learning est la méthode d’apprentissage et le Deep Learning est une technique avancée de Machine Learning.
Cette illustration montre la relation entre Intelligence Artificielle (IA), Machine Learning (ML) et Deep Learning (DL):
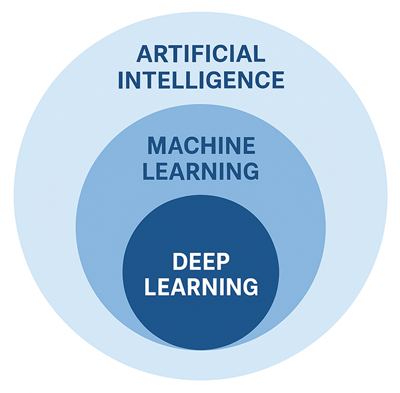
Dans ce cours, nous nous concentrerons exclusivement sur le Machine Learning. Nous explorerons les principaux types d’apprentissage (supervisé, non supervisé, par renforcement), les algorithmes emblématiques (régression, arbres de décision, SVM, k-means…), ainsi que les étapes clés du pipeline ML (de la préparation des données à l’évaluation des modèles). Un cours dédié au Deep Learning est programmé à part.
Prérequis et outils
Ce qu'il est préférable de maitriser avant de commencer
Pour débuter efficacement en Machine Learning, il est vivement recommandé de maîtriser les points suivants:- Les bases en mathématiques: en l'occurrence l'algèbre linéaire (matrices, vecteurs, opérations matricielles...). statistiques et probabilité et calcul différentiel (dérivées et dérivées partielles).
- Programmation: une bonne maîtrise du langage de programmation Python est vivement recommandé. Sinon, vous pouvez suivre mon cours sur ce langage.
Même si les bases mathématiques ne sont pas encore totalement maîtrisées, cela ne constitue pas un frein pour commencer à apprendre le Machine Learning, car les outils que l'on utilisera plus loin dans ce cours, permettent d'automatiser les calculs.
Outils qu'il faut avoir à disposition
Pour pratiquer le Machine Learning, il faut installer Python, un environnement de développement comme Jupyter Notebook (qui permet de coder de façon interactive, visualiser les étapes et documenter le processus) ou VS Code et quelques bibliothèques clés comme NumPy, pandas et scikit-learn. Cependant, l'outil nommé Anaconda est recommandé. Il s'agit d'une distribution qui installe Python, Jupyter ainsi que bibliothèques utiles en une seule fois.Si vous optez pour Anaconda, vous bénéficiez d’une installation simplifiée, car les bibliothèques essentielles au machine learning sont automatiquement incluses. Cela comprend notamment:
- NumPy: Bibliothèque pour le calcul scientifique qui permet de manipuler efficacement des tableaux multidimensionnels (vecteurs et matrices) et d’effectuer des opérations mathématiques rapides.
- Pandas: Outil de manipulation et d’analyse de données tabulaires (comme celles que l'on trouve en Excel), avec des structures comme les DataFrames pour filtrer, transformer et explorer les données.
- matplotlib & seaborn: Bibliothèques de visualisation qui permettent de créer des graphiques (courbes, histogrammes, nuages de points...) pour mieux comprendre les données et les modèles.
- scikit-learn: Bibliothèque de référence qui engobe les modèles de Machine Learning classiques (régression, classification, clustering...) ainsi que les outils du preprocessing, du Feature Engineering et bien plus.
D'autres bibliothèques sont également installées, en l'occurrence TensorFlow et PyTorch, mais nous n'en aurons pas besoin pour le moment car elles sont spécialisées en Deep Learning.
Leçon 1
Intelligence artificielle: Définition, histoire et évolution
Intelligence artificielle: Définition, histoire et évolution

