Intelligence artificielle et Machine Learning: algorithmes et applications






Leçon 18: Le Boosting: principe et mise en pratique avec XGBoost
Toutes les leçons 
Intelligence artificielle et Machine Learning: algorithmes et applications
Leçon 14
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
Leçon 18
Le Boosting: principe et mise en pratique avec XGBoost
Le Boosting: principe et mise en pratique avec XGBoost
Implémenter le Boosting en Machine Learning
Le Boosting: transformer des apprenants faibles en modèles puissants
En machine learning, on distingue généralement deux grandes catégories de modèles:- Les apprenants faibles (weak learners): qui sont des modèles simples, rapides à entraîner mais dont la performance isolée reste limitée, comme par exemple des arbres de décision peu profonds
- Les apprenants forts (strong learners): qui sont des modèles plus complexes capables de bien généraliser et d’obtenir de meilleures prédictions.
Comme on l'a vu dans le leçon précédente sur l'ensemble learning, le boosting est une approche assembliste qui vise précisément à combiner de nombreux apprenants faibles pour construire un apprenant fort. Son principe repose sur un entraînement séquentiel où chaque nouveau modèle corrige les erreurs des précédents en accordant davantage d’importance aux exemples mal prédits. Ainsi, en agrégeant ces modèles simples de manière intelligente, le boosting parvient à produire un modèle global beaucoup plus performant, illustrant la puissance de la collaboration entre plusieurs apprenants faibles pour rivaliser avec des modèles sophistiqués.
XGBoost: une référence incontournable du Boosting
En dépit de la présence de nombreux algorithmes d’apprentissage supervisé qui s'inscrivent dans l'approche du boosting, XGBoost s’est imposé comme l’un des plus performants et des plus utilisés dans la pratique du machine learning.XGboost est une implémentation optimisée du Gradient Boosting, conçue pour être rapide, efficace et capable de traiter de grands volumes de données. Sa popularité tient non seulement à ses excellents résultats en termes de précision et de généralisation, mais aussi à sa flexibilité. En effet, XGBoost permet d’appliquer différents types de fonctions de perte et donne accès à de nombreux autres algorithmes dérivés ou améliorés, tels que LightGBM ou CatBoost qui s’inspirent de ses principes.
Grâce aux optimisations de XGboost (parallélisation, régularisation, gestion des valeurs manquantes...), il est devenu incontournable dans les compétitions de data science et dans les applications industrielles, offrant aux praticiens un outil puissant pour transformer des modèles faibles en modèles robustes et performants. C’est pour cette raison que nous allons traiter XGBoost dans cette leçon à travers un exemple pratique.
Bien que l'on traitera seulement le modèle XGBoost dans cette leçon, le code présenté pourra être facilement adapté pour implémenter les autres variantes du boosting, telles que Gradient Boosting, LightGBM ou CatBoost.
Application de XGBoost pour la classification sur le dataset Titanic
Contrairement à certains modèles de classification qui sont directement intégrés par défaut dans scikit-learn (comme les arbres de décision, les SVM ou les régressions logistiques), XGBoost est une bibliothèque externe spécialisée dans le boosting. Elle a été développée séparément pour offrir des performances optimisées et des fonctionnalités avancées. C’est pour cette raison qu’il est nécessaire de l’installer manuellement avant de pouvoir l’utiliser.Pour installer le modèle XGboost on exécute cette instruction (ou plutôt cette commande):
!pip install xgboost
Dans Jupyter Notebook, le signe ! sert à exécuter une commande du système directement depuis une cellule (comme dans le terminal). Sans le !, Jupyter essaierait d’interpréter pip install xgboost comme du code Python, ce qui provoquerait une erreur.
Comme nous avons déjà étudié en détail le dataset Titanic ainsi que le pipeline nécessaire pour implémenter un modèle de classification, je présenterai directement le code complet et me concentrerai uniquement sur l’explication des éléments nouveaux, en l'occurrence ceux qui concernent l'utilisation du modèle XGBoost.
Je propose le code suivant:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import matplotlib.pyplot as plt
from xgboost import XGBClassifier
df = pd.read_csv("titanic.csv")
df = df[["Survived", "Pclass", "Sex", "Age", "SibSp", "Parch", "Fare"]].dropna()
df["Sex"] = df["Sex"].map({"male": 0, "female": 1})
X = df.drop("Survived", axis=1)
y = df["Survived"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Chargement et entraînement de XGBoost
clf = XGBClassifier(
n_estimators=100,
learning_rate=0.1,
max_depth=3,
random_state=42,
use_label_encoder=False,
eval_metric="logloss"
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Exactitude sur le jeu de test : {accuracy:.2f}")
cm = confusion_matrix(y_test, y_pred)
print(cm)
print(classification_report(y_test, y_pred))
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import matplotlib.pyplot as plt
from xgboost import XGBClassifier
df = pd.read_csv("titanic.csv")
df = df[["Survived", "Pclass", "Sex", "Age", "SibSp", "Parch", "Fare"]].dropna()
df["Sex"] = df["Sex"].map({"male": 0, "female": 1})
X = df.drop("Survived", axis=1)
y = df["Survived"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Chargement et entraînement de XGBoost
clf = XGBClassifier(
n_estimators=100,
learning_rate=0.1,
max_depth=3,
random_state=42,
use_label_encoder=False,
eval_metric="logloss"
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Exactitude sur le jeu de test : {accuracy:.2f}")
cm = confusion_matrix(y_test, y_pred)
print(cm)
print(classification_report(y_test, y_pred))
Voyons la signification des hyperparamètres appliqués au modèle lors de sa création:
- n_estimators=100: Nombre d’arbres de décision (ou itérations de boosting) que le modèle va construire. Plus ce nombre est élevé, plus le modèle peut être précis, mais il risque aussi de tomber dans l'overfitting.
- learning_rate=0.1: Taux d’apprentissage du modèle. Une valeur plus petite (comme 0.01) rend l’apprentissage plus lent mais souvent plus robuste, tandis qu’une valeur plus grande accélère l’entraînement mais peut réduire la généralisation.
- max_depth=3: Profondeur maximale des arbres de décision. Plus la profondeur est grande, plus le modèle peut capturer des relations complexes mais au risque d'overfitting.
- random_state=42: Graine aléatoire pour assurer la reproductibilité des résultats. En fixant cette valeur on obtient toujours le même découpage train/test et le même modèle à chaque exécution.
- use_label_encoder=False: Dans les versions récentes de XGBoost, l’ancien encodeur de labels est déprécié. Mettre ce paramètre à False évite les avertissements et utilise directement les labels fournis.
- eval_metric="logloss": Métrique d’évaluation utilisée pendant l’entraînement. Ici, on utilise la logarithmic loss (logloss) adaptée aux problèmes de classification binaire. Elle mesure la différence entre les probabilités prédites et les vraies classes (plus la valeur est faible, meilleur est le modèle).
Un label encoder est une technique de prétraitement des données en machine learning qui sert à transformer des variables catégorielles en valeurs numériques. Nous aurons l'occasion de la voir en détail dans la leçon consacrée au preprocessing.
L'exécution du code produit ces résultats:
Exactitude sur le jeu de test : 0.80
[[ 74 13 ]
[ 15 41 ]]
[[ 74 13 ]
[ 15 41 ]]
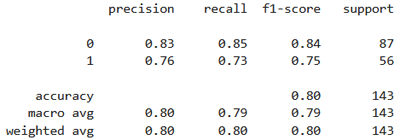
Le modèle est globalement performant, mais il fait presque autant d’erreurs sur les survivants (15 faux négatifs) que sur les non‑survivants (13 faux positifs). Dans tous les cas, je vous laisse le soin de comparer les résultats obtenus en utilisant XGBoost avec les résultats obtenus en utilisant les modèles classiques vus précédemment.
Leçon 14
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
Leçon 18
Le Boosting: principe et mise en pratique avec XGBoost
Le Boosting: principe et mise en pratique avec XGBoost


