Intelligence artificielle et Machine Learning: algorithmes et applications






Leçon 23: Apprentissage non supervisé: Explorer et regrouper les données sans supervision
Toutes les leçons 
Intelligence artificielle et Machine Learning: algorithmes et applications
Leçon 14
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
Leçon 23
Apprentissage non supervisé: Explorer et regrouper les données sans supervision
Apprentissage non supervisé: Explorer et regrouper les données sans supervision
Apprentissage non supervisé: Découvrir la structure cachée des données
Qu'est ce que l'apprentissage non supervisé?
Dans l’apprentissage supervisé, nous avons vue que le modèle apprend à partir d’exemples annotés où chaque observation est accompagnée d’une étiquette qui représente la "bonne réponse" qui guide l’algorithme (comme le prix d'un bien immobiler en fonction de ses caractéristiques, l'espèce d'une plante ou encore le fait fait qu'un passager du Titanic ait survecu ou non).L’apprentissage non supervisé (Unsupervised Learning) repose sur une logique fondamentalement distincte de celle de l’apprentissage supervisé. Dans ce cadre, aucune étiquette n’est disponible pour guider le modèle, ce qui signifie qu'il n’existe pas de variable cible à prédire ni de référence explicite permettant d’évaluer directement la qualité des regroupements ou des structures identifiées. L’algorithme doit donc inférer par lui‑même l’organisation interne des données et mettre en évidence les régularités qui les caractérisent.
On peut comparer cela à une grande boîte remplie d’objets variés mais sans indication sur leur nature ou leur usage. Sans consigne précise, la première étape consiste à observer, comparer et regrouper ce qui se ressemble, repérer ce qui paraît inhabituel ou trouver une manière simple de représenter l’ensemble. L’objectif n’est donc pas de prédire quelque chose, mais de découvrir ce que les données révèlent naturellement.
Grâce à cette approche, l’apprentissage non supervisé permet d’explorer un jeu de données, d’identifier des structures cachées et de mieux comprendre ce qu’il contient. C’est une étape essentielle lorsqu’on ne dispose pas de labels, mais aussi un complément précieux pour préparer ou enrichir des modèles supervisés.
Comprendre la structure intrinsèque des données en absence de labels
L’absence totale de labels modifie en profondeur la nature même du problème d’apprentissage. Dans un cadre supervisé, l’objectif consiste à apprendre une fonction qui relie explicitement des entrées à une sortie connue. En non supervisé, cette relation n’existe plus. En effet, l’algorithme ne dispose d’aucune indication sur ce qu’il doit prédire. Il se retrouve face à des données brutes qu’il doit analyser pour en extraire des formes, des tendances ou des structures récurrentes. L’apprentissage ne repose donc plus sur l’imitation d’une réponse correcte, mais sur la découverte autonome de l’organisation interne du jeu de données.Dans ce contexte, l’algorithme cherche à mettre en évidence des régularités, à repérer des observations qui s’écartent du comportement général, ou encore à simplifier la représentation des données pour en faciliter l’analyse. Cette démarche transforme l’apprentissage non supervisé en un véritable outil d’exploration. Il permet de mieux comprendre la structure intrinsèque d’un dataset, d’identifier des groupes naturels, de révéler des dimensions cachées ou de détecter des éléments atypiques. Ces informations peuvent ensuite servir à formuler des hypothèses, orienter des analyses plus poussées ou guider la préparation de données pour des modèles supervisés.
Ainsi, l’apprentissage non supervisé occupe une place essentielle dans tout pipeline de data science, en particulier lorsque les données sont nombreuses, complexes ou encore mal comprises. Il constitue souvent la première étape pour éclairer la nature des informations disponibles, réduire leur complexité ou enrichir les futures variables utilisées dans des modèles prédictifs.
Applications de l'apprentissage non superviséClustering: regrouper les données par similarité
Le clustering consiste à regrouper automatiquement les observations en fonction de leur ressemblance sans connaître à l’avance les catégories. C’est une méthode précieuse pour segmenter des clients, identifier des profils types ou explorer des structures cachées dans les données. Les algorithmes de clustering analysent les distances ou les densités pour former des groupes cohérents. Cette approche est largement utilisée en marketing, biologie, sociologie ou encore en traitement d’image. Elle est utile à chaque fois qu’on cherche à comprendre comment les données s’organisent naturellement.
Cette figure simplifiée illustre le clustering en groupant des données similaires:
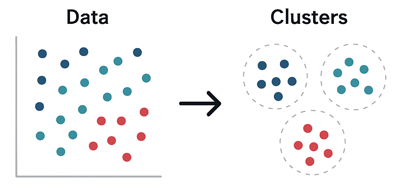
On voit clairement la transformation opérée par l’apprentissage non supervisé. En effet, des données complexes et désorganisées au départ deviennent structurées et regroupées par similarité à la fin.
Parmi les algorithmes de clustering les plus répandus, on peut citer k-means, DBSCAN et Spectral Clustering.
Détection d’anomalies (Outlier detection): repérer l’inhabituel
La détection d’anomalies (appelée aussi détection de valeurs aberrates ou Outier Detection) vise à identifier les observations qui s’écartent fortement du comportement général. Ces outliers peuvent correspondre à des erreurs, des fraudes, des pannes ou des événements rares. En l’absence de labels, les algorithmes non supervisés évaluent la densité locale, l’isolement ou la distance aux autres points pour repérer ce qui semble anormal. Cette application est cruciale dans les domaines de la cybersécurité, de la finance, de la maintenance prédictive ou du contrôle qualité.
Cette figure illustre la détections d'éléments aberrants dans les données:
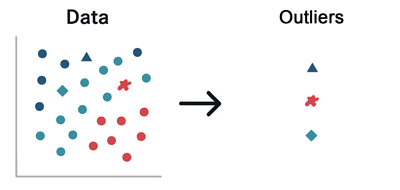
Le modèle arrive à repérer automatiquement les observations qui ne suivent pas le comportement général du jeu de données et les considère comme des anomalies ou des valeurs aberrantes.
Parmi les algorithmes les plus utilisés pour la détection d’outliers, on retrouve Isolation Forest, Local Outlier Factor (LOF) et One‑Class SVM.
Réduction de dimension: simplifier la représentation des données sans perdre de l'information
La réduction de dimension permet de projeter des données complexes dans un espace plus simple tout en conservant leur structure informative. Elle est utilisée pour faciliter la visualisation, accélérer les calculs ou améliorer la performance d’autres algorithmes. Les algorithmes qui s'inscrivent dans cette classes permettent généralement de représenter des données multidimensionnelles en 2D ou 3D, révélant ainsi des regroupements ou des tendances invisibles dans l’espace initial. Cette étape est souvent intégrée dans les pipelines de machine learning pour mieux comprendre les données ou préparer un clustering plus efficace.
Cette figure illustre le processus de réduction de dimensionnalité à travers cette famille d'algorithmes:
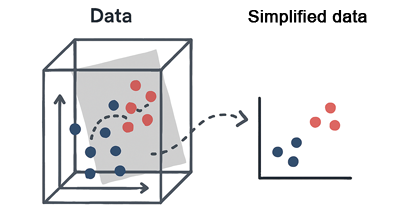
On voit explicitement le principe de réduction de dimension où on part d’un nuage de points en 3D, projeté sur un plan 2D, ce qui rend les regroupements deviennent plus visibles.
Parmi les méthodes de réduction de dimension les plus utilisées, on retrouve PCA, t‑SNE et UMAP.
Dans les leçons qui suivent, nous étudierons en détail et à travers la pratique chacune de ces catégories d’apprentissage non supervisé en nous appuyant sur les algorithmes les plus connus.
Leçon 14
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
Leçon 23
Apprentissage non supervisé: Explorer et regrouper les données sans supervision
Apprentissage non supervisé: Explorer et regrouper les données sans supervision
")

