Intelligence artificielle et Machine Learning: algorithmes et applications






Leçon 10: Séparation du jeu de données en ensembles d'entraînement et de test
Toutes les leçons 
Intelligence artificielle et Machine Learning: algorithmes et applications
Leçon 10
Séparation du jeu de données en ensembles d'entraînement et de test
Séparation du jeu de données en ensembles d'entraînement et de test
Découpage des données pour entraîner et tester le modèle
Pourquoi diviser le dataset?
Lorsqu’on conçoit un modèle de Machine Learning, l’objectif n’est pas seulement de le faire fonctionner sur les données qu’on lui fournit, mais surtout qu’il soit capable de généraliser ses prédictions à de nouvelles données jamais vues. Autrement dit, on cherche à évaluer sa capacité à apprendre des tendances sous-jacentes plutôt qu’à mémoriser des exemples. On parle dans ce cas de la capacité du modèle à généraliser ses prédictions.Reprenons le cas d’un modèle de régression linéaire simple qu'on a déjà traité avant et dont le but est d’estimer le prix d’une maison en fonction de sa superficie.
Le jeu de données d’entraînement contient les superficies suivantes:
[30, 50, 70, 90, 110, 130, 150]
et les prix correspondants sont:
[100, 140, 220, 240, 290, 360, 400]
Une fois le modèle entraîné sur ces données, si on lui demande de prédire le prix d’une maison de 50m², il pourrait tout simplement renvoyer 140, car cette valeur figure déjà dans le jeu d’entraînement. Cela semble cohérent et les performances du modèle semblent excellentes car les prédictions collent parfaitement avec les valeurs réelles.
Cependant, cette situation est trompeuse car elle ne nous dit rien sur la capacité du modèle à généraliser, c’est-à-dire à faire des prédictions fiables sur des cas qu’il n’a jamais rencontrés. Par exemple, si on lui soumet une superficie de 75m², qui ne figure pas dans le jeu d’entraînement, alors sa prédiction pourrait être approximative, voire erronée.
Pour cette raison, on doit procéder à la séparation les données en deux ensembles: un pour l’entraînement et un autre pour l’évaluation. Cela permet de vérifier si les performances du modèle sur des données nouvelles sont cohérentes avec celles observées pendant sa phase de conception. En d'autres termes, on s’assure que le modèle ne se contente pas de "réciter" ce qu’il a appris, mais qu’il est capable de raisonner et extrapoler de manière pertinente.
Cette figure illustre le processus de division du dataset en deux lots, un train set et un test set:
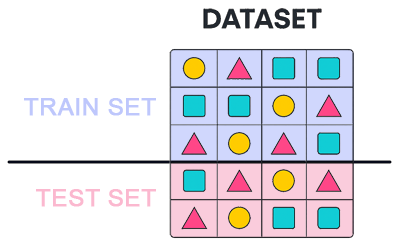
Utlisation de la fonction train_test_split de scikit-learn
La fonction train_test_split, issue de la bibliothèque scikit-learn, permet de diviser un jeu de données en deux parties: une pour entraîner le modèle (appelée train set) et une pour l’évaluer (connue sous le nom de test set). La fonction train_test_split est essentielle pour tester la capacité d’un modèle à généraliser sur des données nouvelles qu'il n'a pas vu lors de son entrainement.La fonction train_test_split est facile à prendre en main. Voyons rapidement comment elle fonctionne avant d’illustrer son usage avec un exemple concret.
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.2)
Après avoir importé la fonction train_test_split depuis le sous-module model_selection de la bibliothèque scikit-learn, on procède à la division du jeu de données, représenté par X (les variables explicatives ou features) et y (la variable cible ou target), afin de séparer les données d’entraînement de celles destinées à l’évaluation.
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.2)
L'argument train_size représente la proportion de données du dataset utilisée pour le test set (dans ce cas 20% de l'ensemble de données).
Il est recommandé que le pourcentage de données dedié au train set soit plus important, car le modèle a souvent besoin d'une grande quantité de données afin de s'entrainer efficacement et capter le maximum de subtilités et de régularités que celles-ci présentent.
La fonction train_test_split retourne un tuple de 4 éléments:
- X_train: Features déstinées à l’entraînement
- X_test: Features déstinées au test
- y_train: Cibles (target) pour l’entraînement
- y_test: Cibles (target) pour le test
L’ordre des éléments retournés par train_test_split est strictement défini et doit être respecté afin de ne pas se retrouver avec des données incohérentes.
Il est toutefois possible de spécifier des aguments supplémenraires à la fonction train_test_split comme:
- train_size: similaire à test_size, mais avec un effet inversé. Elle permet de spécifier la proportion de données dédiée au train set. Il est préférable de ne spécifier que l'un d'entre eux afin d'éviter des valeurs contradictoires.
- shuffle: mélange les données avant de les diviser (il vaut True par défaut)
- random_state: fixe la graine aléatoire et garantit que le découpage des données soit reproductible à chaque exécution. En d'autres termes, à chaque exécution du code, on reproduit exactement les mêmes données pour le train set et le test set. C'est très utile quand on veut réentrainer et évaluer le modèle sur les mêmes données en modifiant à chaque fois ses hyperparamètres. L'argument random_state accepte un entier (souvent la valeur 42 préférée par les datascientists).
- stratify: permet de conserver la proportion des classes dans les deux ensembles (très utile dans les problèmes de classification). Il sert à équilibrer les données. Par exemple, si on dispose de 90 % de classe A et 10 % seulement de classe B dans nos données, un découpage aléatoire sans stratification peut produire un test set qui ne contient presque pas de classe B, ce qui faussera certainement l’évaluation du modèle.
Dans le leçon qui va suivre, nous allons mettre en pratique le découpage de données avec train_test_split à travers un exemple concret. Nous allons également invoquer quelques techniques supplémentaires qui permettent de modifier certaines valeurs de notre dataset afin de les adapter au modèle de régression.
Leçon 10
Séparation du jeu de données en ensembles d'entraînement et de test
Séparation du jeu de données en ensembles d'entraînement et de test


