Intelligence artificielle et Machine Learning: algorithmes et applications






Leçon 4: Analyse exploratoire des données (EDA)
Toutes les leçons 
Intelligence artificielle et Machine Learning: algorithmes et applications
Leçon 4
Analyse exploratoire des données (EDA)
Analyse exploratoire des données (EDA)
L'analyse exploratoire de données - EDA
Pourquoi l’EDA est une étape incontournable en Machine Learning
L’analyse exploratoire des données (ou Exploratory Data Analysis - EDA) est une étape fondamentale dans tout projet de Machine Learning. Avant de passer à la construction d’un modèle, il faut d’abord examiner les données disponibles pour en saisir la structure, les types de variables, et les éventuelles irrégularités. Cette phase permet de repérer des problèmes comme des valeurs manquantes, des incohérences ou des relations inattendues entre les variables. En quelque sorte, l’EDA joue le rôle d’un repérage initial. C'est un peu comme un ingénieur qui étudie le terrain avant de bâtir un pont. Donc, on explore les données pour mieux orienter les choix futurs.On peut définir l’EDA comme étant l’ensemble des méthodes utilisées pour explorer, comprendre et résumer les caractéristiques principales d’un jeu de données, souvent à l’aide de visualisations.
L'analyse exploratoire des données intervient généralement avant le prétraitement et la modélisation, et sert à orienter les choix techniques en fonction des observations.
Méthodes et visualisations clés pour explorer les données
L’analyse exploratoire des données peut se faire à plusieurs niveaux, chacun apportant un éclairage différent sur le jeu de données:- Analyse univariée: consiste à examiner une seule variable à la fois. Elle permet de comprendre sa distribution, ses valeurs extrêmes, sa tendance centrale (moyenne, médiane) et sa dispersion. Par exemple, un histogramme ou un boxplot peut révéler si une variable est bien répartie ou si elle contient des valeurs anormales.
- L’analyse bivariée: explore les relations entre deux variables. Elle permet de voir s’il existe une corrélation, une dépendance ou une interaction entre elles. Des outils comme les scatter plots ou les tableaux croisés sont utiles pour visualiser ces liens.
- L’analyse multivariée: étudie plusieurs variables en même temps. Elle est utile pour détecter des regroupements, des structures cachées ou des combinaisons de variables qui influencent un phénomène. Des techniques comme les pairplots ou les cartes de chaleur (heatmaps) facilitent cette exploration.
Pour réaliser ces analyses, on utilise des bibliothèques comme Pandas, Seaborn, Matplotlib ou Plotly. Ces outils permettent de créer des graphiques clairs et interactifs qui ne servent pas seulement à illustrer les données, mais à en révéler les tendances, les anomalies et les relations invisibles à première vue.
Nous aurons l'occasion d'explorer régulièrement ces outils-là quand on aura arrivé à la partie implémentation du pipeline de Machine Learning avec du code Python.
Détecter les pièges et anomalies avant la modélisation
L’analyse exploratoire des données ne sert pas seulement à mieux comprendre le dataset mais elle joue aussi un rôle de contrôle. En examinant les données en profondeur, on peut repérer plusieurs types de problèmes qui risquent d’altérer les performances du modèle. Par exemple, les valeurs manquantes peuvent empêcher certains algorithmes de fonctionner correctement ou introduire des biais. Les valeurs aberrantes (outliers), quant à elles, peuvent fausser les moyennes ou les relations entre variables (surtout dans les modèles sensibles aux extrêmes).L’EDA permet aussi d’identifier les variables redondantes (qui apportent la même information) ou peu informatives (qui ne varient presque pas). Ces variables peuvent alourdir inutilement le modèle ou le rendre moins interprétable. C’est pourquoi il est essentiel d’apprendre à les détecter, à comprendre leur impact potentiel et à choisir une stratégie adaptée (suppression, transformation ou imputation).
Cette figure illustre le pipeline EDA en gros:
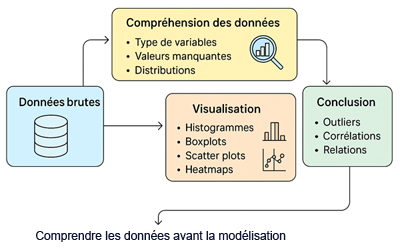
En résumé, l’EDA agit comme un filtre intelligent avant la modélisation. Elle aide à nettoyer, simplifier et fiabiliser les données pour que le modèle repose sur une base solide et cohérente.
Leçon 4
Analyse exploratoire des données (EDA)
Analyse exploratoire des données (EDA)


