Intelligence artificielle et Machine Learning: algorithmes et applications






LeûÏon 3: Qu'est-ce qu'un dataset? Tout commence par les donnûˋes
Toutes les leûÏons 
Intelligence artificielle et Machine Learning: algorithmes et applications
LeûÏon 3
Qu'est-ce qu'un dataset? Tout commence par les donnûˋes
Qu'est-ce qu'un dataset? Tout commence par les donnûˋes
Le dataset : la matiû´re premiû´re du Machine Learning
Qu'est ce qu'un dataset?
Un dataset (ou jeu de donnûˋes) est un ensemble structurûˋ de donnûˋes utilisûˋ pour entraûÛner, valider et tester les modû´les dãapprentissage automatique. Il se prûˋsente gûˋnûˋralement sous forme de tableau oû¿ chaque ligne reprûˋsente une observation (ou un exemple). Les donnûˋes d'un dataset sont gûˋnûˋralement liûˋes û un sujet ou û un projet spûˋcifique. Ils peuvent inclure diffûˋrents types d'informations, comme des chiffres, du texte, des images etc...Selon le type dãapprentissage (supervisûˋ, non supervisûˋ, par renforcement), le dataset peut contenir des annotations explicites, des donnûˋes brutes ou des retours dãinteraction. Bien le comprendre et le prûˋparer est une ûˋtape cruciale dans tout projet dãintelligence artificielle.
Cette figure illustre un exemple (simplifiûˋ) de dataset structurûˋ avec 3 variables explicatives (features) et une ûˋtiquette (label). Ce dataset est principalement adaptûˋ û un apprentissage supervisûˋ:
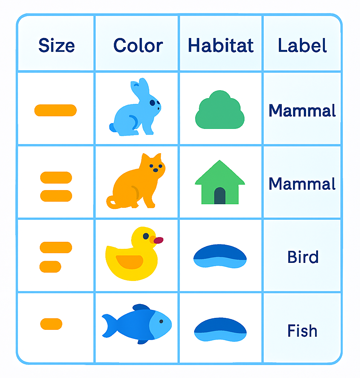
Une variable explicative est une caractûˋristique utilisûˋe pour prûˋdire ou influencer une autre variable appelûˋe variable cible (ou variable dûˋpendante). Elle joue le rûÇle dãentrûˋe dans un modû´le de Machine Learning ou une ûˋtude statistique.
Structure d'un dataset
Les datasets sont gûˋnûˋralement organisûˋs sous forme de tableaux similaires û des feuilles de calcul ou des tables de bases de donnûˋes. Dans cette structure :- Chaque ligne correspond û une observation ou un enregistrement individuel.
- Chaque colonne reprûˋsente une variable ou un attribut spûˋcifique. Par exemple, dans un dataset de ventes, on peut retrouver des colonnes telles que "ID produit", "Prix", "Date dãachat"...
- Chaque cellule contient une valeur unique. Il s'agit de la donnûˋe elle mûˆme.
Les jeux de donnûˋes peuvent ûˆtre classûˋs selon leur structure et leur contenu, ce qui influence directement leur traitement et leur usage en Machine Learning :
- Donnûˋes structurûˋes: Organisûˋes dans un format rigide et prûˋdûˋfini, comme des tableaux avec lignes et colonnes. Ce type est idûˋal pour lãanalyse statistique et les applications classiques de business intelligence.
- Donnûˋes non structurûˋes: Ne suivent aucun schûˋma fixe. Elles incluent des textes libres, des images, des sons ou des vidûˋos. Ces donnûˋes sont essentielles pour entraûÛner des modû´les avancûˋs dãintelligence artificielle.
- Donnûˋes semi-structurûˋes: Reprûˋsentent un compromis entre les deux types prûˋcûˋdents. Elles utilisent des balises ou des marqueurs (comme dans les fichiers JSON ou XML) pour organiser lãinformation sans respecter une structure relationnelle stricte.
- Donnûˋes numûˋriques: Composûˋes uniquement de valeurs quantitatives comme des relevûˋs de tempûˋrature, des mesures physiques ou des donnûˋes financiû´res.
- Donnûˋes catûˋgorielles: Reprûˋsentent des groupes ou des classes discrû´tes, comme le sexe, la couleur, ou le type de produit. Elles sont souvent encodûˋes pour ûˆtre utilisûˋes dans les modû´les de Machine Learning.
- Sûˋries temporelles: Enregistrent des donnûˋes û intervalles rûˋguliers sur une pûˋriode donnûˋe. Elles permettent dãanalyser les tendances, les variations et les prûˋvisions (par exemple: ûˋvolution des cours boursiers, estimation du chiffre d'affaire d'une entreprise...).
Dans le cours de Preprocessing et Feature Engineering, nous aborderons le processus dãencodage et de transformation des donnûˋes qui constituent une ûˋtapes essentielles avant leur prûˋsentation û un modû´le de Machine Learning. Ces manipulations font partie intûˋgrante de ce quãon appelle le feature engineering, cãest-û -dire lãart dãoptimiser les variables explicatives pour amûˋliorer la performance des algorithmes.
Oû¿ trouver les datasets pour entrainer les modû´les de Machine Learning?
Les datasets sont disponibles sur de nombreuses plateformes ouvertes ou spûˋcialisûˋes, selon le domaine dãapplication. Les plus connues sont:- Kaggle: Plateforme collaborative avec des milliers de datasets publics, souvent accompagnûˋs de codes (notebooks) et de discussions. Il s'agit certainement de la plateforme la plus populaire au milieu des datascientists.
- UCI Machine Learning Repository: Collection historique de datasets acadûˋmiques utiles pour tester des algorithmes classiques.
- OpenML: Plateforme ouverte pour partager, explorer et comparer des datasets et des modû´les.
- Google Dataset Search: Moteur de recherche de Google qui facilite aux chercheurs de localiser les datasets sur le Web.
- Hugging Face Datasets: Bibliothû´que Python pour accûˋder û des datasets NLP, vision, audio, etc. Compatible avec PyTorch et TensorFlow (deux ûˋcosystû´mes largement utilisûˋes pour le Deep Learning).
Il existe ûˋgalement des sources institutionnelles et gouvernementales comme:
- data.gouv.fr: Plateforme de diffusion de donnûˋes publiques (open data) de l'ûtat franûÏais lancûˋe la premiû´re fois en 2011.
- World Bank Open Data: La plateforme principale de la Banque mondiale pour accûˋder aux donnûˋes mondiales sur le dûˋveloppement.
Donnûˋes dynamiques extraites du Web - Web scraping
Certaines donnûˋes ne sont pas disponibles sous forme de fichiers statiques prûˆts û l'emplois, mais peuvent ûˆtre extraites en temps rûˋel depuis des plateformes en ligne grûÂce û des APIs ou des techniques de web scraping. Ces mûˋthodes permettent de collecter des informations actualisûˋes.Les donnûˋes extraites sont souvent utiles pour des projets en traitement du langage naturel (NLP) ou en analyse comportementale. Les API les plus populaires sont:
- Twitter API: Pour rûˋcupûˋrer des tweets, hashtags, profils ou tendances et analyser les opinions ou les dynamiques sociales.
- Reddit API: Utile pour explorer des discussions communautaires, des votes ou des contenus textuels riches.
- Yelp API: Permet dãobtenir des avis de millions de clients û travers le monde, des informations sur les commerces et des donnûˋes gûˋolocalisûˋes.
LeûÏon 3
Qu'est-ce qu'un dataset? Tout commence par les donnûˋes
Qu'est-ce qu'un dataset? Tout commence par les donnûˋes
 Quiz
Quiz 
")
