Intelligence artificielle et Machine Learning: algorithmes et applications






Leçon 2: Types d'apprentissage: supervisé, non supervisé et par renforcement
Toutes les leçons 
Intelligence artificielle et Machine Learning: algorithmes et applications
Leçon 2
Types d'apprentissage: supervisé, non supervisé et par renforcement
Types d'apprentissage: supervisé, non supervisé et par renforcement
Principaux types d'apprentissage: supervisé, non supervisé et par renforcement
Apprentissage supervisé (Supervised Learning)
L’apprentissage supervisé (Supervized Learning) est l’une des approches les plus répandues en Machine Learning. Il consiste à entraîner un modèle à partir d’un ensemble de données annotées, c’est-à-dire des exemples pour lesquels la réponse correcte (ou "étiquette") est déjà connue.Le but de l'apprentissage supervisé est que le modèle apprenne à associer les entrées (dites features) aux sorties attendues (labels) afin de pouvoir prédire correctement de nouvelles données qu'il n'a jamais vues. Cette méthode est utilisée dans des tâches comme la classification (identification de spams, diagnostic de maladies...) ou la régression (prédiction du prix d’un bien immobilier, prévision de ventes...) à travers des algorithmes comme la régression linéaire et logistique, les arbres de décision, K-Nearest Neighbors, Naive Bayes, SVM...
L’efficacité de l’apprentissage supervisé dépend fortement de la qualité des données, du choix des algorithmes et des métriques d’évaluation. On peut dire que l'apprentissage supervisé constitue une approche intuitive proche de l’enseignement humain où on montre des exemples, on corrige les erreurs et le système s’améliore progressivement.
Cette figure illustre le processus d’apprentissage supervisé avec données annotées:
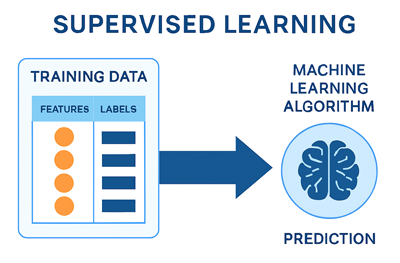
Les prochaines leçons aborderont en profondeur la structure des données d’entraînement, les principaux algorithmes de Machine Learning ainsi que les métriques utilisées pour évaluer leurs performances.
Apprentissage non supervisé (Unsupervised Learning)
L’apprentissage non supervisé (Unsupervised Learning) est une approche du Machine Learning dans laquelle les données utilisées ne sont pas annotées. En effet, les exemples d'entrainement ne comportent pas de réponses ou de catégories prédéfinies. Le modèle doit alors découvrir par lui-même des structures ou des régularités cachées dans les données (on utilise souvent les expressions subtilités ou schémas récurrents).L'apprentissage non supervisé est particulièrement utile pour explorer, segmenter ou réduire la complexité de grands ensembles d’informations. Les algorithmes les plus courants incluent le clustering (regroupement automatique d’éléments similaires) via des algorithmes comme K-means ou DBSCAN, la détection des valeurs aberrantes dans les données (appelées aussi outliers) en utilisant des algorithmes comme Isolation Forest ou Local Outlier Factor (LOF), et la réduction de dimensionnalité via des algorithmes comme PCA ou LDA.
Contrairement à l’apprentissage supervisé, il n’y a pas de "bonne réponse" à apprendre, mais plutôt une capacité à révéler des schémas, des groupes ou des corrélations inattendues. L'apprentissage non supervisé est souvent considéré comme une approche exploratoire qu'on utilise généralement en phase de découverte ou de prétraitement.
Cette figure illustre le processus d’apprentissage non supervisé:
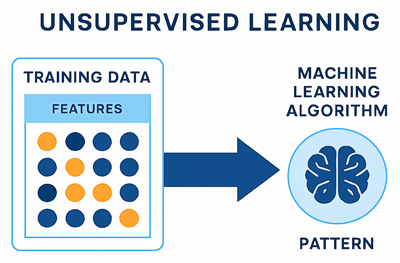
Encore une fois, je rappelle que tous les détails concernant l'apprentissage non supervisés seront traités en profondeur dans les prochaines leçons.
Apprentissage par renforcement (Reinforcement learning)
L’apprentissage par renforcement (Reinforcement Learning) est une approche du Machine Learning dans laquelle un agent autonome apprend à prendre des décisions en interagissant avec un environnement.Contrairement aux méthodes supervisées ou non supervisées, le modèle n’a pas accès à des exemples prêts (annotés ou non annotés), mais reçoit des récompenses ou punitions en fonction des actions qu’il entreprend.
L’objectif est de maximiser les récompenses cumulées sur le long terme en découvrant une stratégie optimale (ou policy) par essais-erreurs. Ce type d’apprentissage est particulièrement adapté aux situations dynamiques et séquentielles comme les jeux vidéo ou la robotique. Il repose sur des concepts clés comme les états, actions, récompenses et utilise des algorithmes tels que Q-learning, SARSA (State-Action-Reward-State-Action), Actor-critic ou les méthodes basées sur les gradients.
L’apprentissage par renforcement combine exploration et exploitation et s’inspire fortement des mécanismes d’apprentissage comportemental observés chez les êtres vivants.
Cette figure illustre le processus d’apprentissage par renforcement:
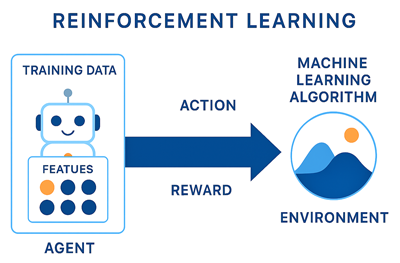
Il y a aussi l'apprentissage semi-supervisé et auto-supervisé
En plus des approches classiques supervisée, non supervisée et par renforcement, le Machine Learning comprend également des formes hybrides comme l’apprentissage semi-supervisé et l’apprentissage auto-supervisé.Le semi-supervisé (Semi-supervised Learning) utilise un petit nombre de données annotées combinées à un grand volume de données non annotées. Cette approche permet d’améliorer les performances tout en réduisant le coût d’annotation. En effet, l'annotation (ou étiquetage) des données est, dans la plupart du temps, une tâche réalisée manuellement. Par conséquent, elle est souvent coûteuse en temps et en effort.
L’auto-supervisé (Self-supervised Learning) quant à lui, génère automatiquement des tâches d’apprentissage à partir des données elles-mêmes, souvent en prétextant des objectifs internes (comme prédire une partie manquante). Ces méthodes sont particulièrement utiles dans les contextes où les données annotées sont rares ou coûteuses à obtenir.
Leçon 2
Types d'apprentissage: supervisé, non supervisé et par renforcement
Types d'apprentissage: supervisé, non supervisé et par renforcement


