Intelligence artificielle et Machine Learning: algorithmes et applications






Leçon 14: k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
Toutes les leçons 
Intelligence artificielle et Machine Learning: algorithmes et applications
Leçon 14
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
k-NN: classification par voisinage sans apprentissage explicite
Définition et principe de fonctionnement de l'algorithme k-NN
k-Nearest Neighbors ou k-NN (qui signifie les k plus proches voisins) est un algorithme d’apprentissage supervisé utilisé pour la classification. Il est apprécié pour sa simplicité et son intuitivité. En effet, il ne construit pas de modèle explicite, mais prend ses décisions en comparant un nouvel exemple aux données déjà observées. Son principal atout est qu’il peut s’adapter à des formes de décision complexes en s’appuyant sur la structure locale des données.Le principe du k-NN est le suivant: lorsqu’un nouvel exemple doit être classé, le modèle recherche les k exemples les plus proches dans les données d’entraînement, puis lui attribue la classe la plus fréquente parmi ces voisins.
Bien que l’algorithme k-NN soit souvent associé à la classification, il peut également être utilisé pour la régression. Dans ce cas, au lieu de voter pour une classe, il prédit une valeur numérique en calculant la moyenne des valeurs cibles des k voisins les plus proches. Le résultat est alors une valeur continue typique d’un problème de régression.
Algorithme non paramétrique basé sur les distances
k-NN est un algorithme non paramétrique, ce qui signifie qu’il ne cherche pas à apprendre une fonction ou des paramètres à partir des données. Contrairement à la régression logistique qui ajuste des coefficients pour modéliser une frontière de décision entre les classes, k-NN ne construit aucun modèle, mais il conserve simplement les exemples d’entraînement en mémoire et les utilise pour faire des prédictions.Lorsqu’un nouvel exemple doit être classé, k-NN recherche les k exemples les plus proches dans les données selon une mesure de distance. La classe majoritaire parmi ces voisins est alors attribuée à l’exemple. La distance euclidienne est la plus courante, mais d’autres distances comme Manhattan ou cosinus peuvent être utilisées selon le type de données.
Dans cette illustration, le cercle vert (le point à classer) est entouré de quatre voisins mis en évidence (ce qui correspond à k=4) dans l’algorithme k-NN. Le modèle prendra en compte ces quatre points pour déterminer la classe majoritaire (rouge) et effectuer la prédiction.
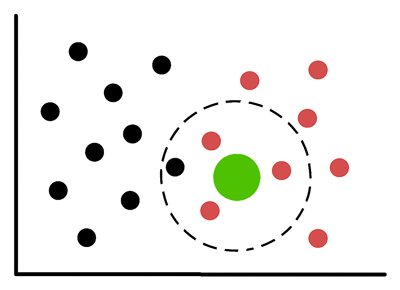
La dépendance à la distance rend l’algorithme k-NN sensible à l’échelle des variables et à la dimensionnalité. C'est pour cette raison qu'on est souvent amené à procéder à une bonne normalisation des variables.
La normalisation consiste à ramener toutes les variables à la même échelle (souvent entre 0 et 1 ou avec une moyenne nulle et une variance égale à 1). Cela évite qu’une variable à grande amplitude (comme le revenu) domine une autre plus discrète (comme l’âge) dans les calculs de distance ou d’optimisation. Nous verrons cette technique dans la partie du cours consacré au pré-processing.
Distance d'Euclide et distance de Manhattan
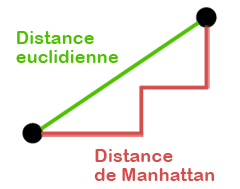
La distance euclidienne et la distance de Manhattan sont parmi les plus utilisées en k-NN, surtout dans les contextes classiques de classification supervisée.La distance d'Euclide (ou distance euclidienne) est la distance "à vol d’oiseau" entre deux points dans l’espace. Elle mesure la longueur du segment droit qui les relie.
La distance entre deux point \(x\) et \(y\) représentées par les coordonnées \((x_1,x_2...), (y_1,y_2...)\) est exprimée par cette formule:
\(d(x,y)=\sqrt{(x_1-y_1)^2+(x_2-y_2)^2+\dots +(x_n-y_n)^2}\)
Cette distance est très utilisée quand les variables sont continues et normalisées. Elle fonctionne bien si toutes les dimensions ont une importance comparable.
La distance de Manhattan, quant à elle, simule le déplacement dans une ville quadrillée (comme Manhattan) où on ne peut pas couper à travers les blocs mais on avance horizontalement et verticalement.
La distance Manhattan est représentée par cette formule:
\(d(x,y)=|x_1-y_1|+|x_2-y_2|+\dots +|x_n-y_n|\)
Cette distance est utile quand les variables sont discrètes ou quand les déplacements diagonaux n’ont pas de sens. Elle est aussi plus robuste aux valeurs extrêmes que la distance euclidienne.
Cette illustratin montre deux points reliés par deux chemins différents: un segment droit pour la distance euclidienne (le chemin à vol d'oiseau et le plus court), et un chemin en escalier pour la distance de Manhattan (comme dans une ville quadrillée).
Comment choisir une valeur optimale de l'hyperparamètre k dans k-NN?
Le choix du bon k dans k-NN est crucial pour l’équilibre entre la précision et la robustesse. En effet, un k trop petit (par exemple k=1) rend le modèle très sensible au bruit, à titre d'exemple, un seul voisin erroné peut fausser la prédiction. Inversement, un k trop grand dilue l’influence locale et peut brouiller les frontières entre classes, surtout si les classes sont déséquilibrées.Le paramètre k dans l’algorithme k-NN est ce qu’on appelle un hyperparamètre. Contrairement aux paramètres internes appris automatiquement par un modèle (comme les poids dans une régression logistique), un hyperparamètre est une valeur fixée manuellement avant l’entraînement.
En général, on détermine l'hyperparamètre k expérimentalement, souvent à l’aide de la méthode du coude (elbow method) ou par validation croisée.
- Validation croisée (cross-validation): On teste plusieurs valeurs de k sur des sous-ensembles des données et on choisit celle qui minimise l’erreur moyenne.
- Méthode du coude (elbow method): On trace l’erreur de classification en fonction de k. Le point où l’erreur cesse de diminuer significativement (le "coude") est souvent un bon choix.
La validation croisée et la méthode du coude ne sont pas propres à k-NN. Elles sont généralement applicables à d’autres algorithmes d’apprentissage, notamment ceux qui nécessitent le réglage d’hyperparamètres. Nous les explorerons plus en détail plus loin dans ce cours.
Élaboration d’un k-NN pour la classification supervisée
Classification du dataset Iris avec k-NN
Comme dans les deux leçons précédentes, nous allons à nouveau utiliser le dataset Iris.Cette fois-ci, le code sera présenté en un seul bloc, puisque vous en connaissez désormais ses différentes composantes:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
cm=confusion_matrix(y_test,y_pred)
print(cm)
Nous avons fixé l'hyperpamètre k à 3. Il s'agit d'un choix arbitraire mais fréquemment pertinent pour débuter.
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
cm=confusion_matrix(y_test,y_pred)
print(cm)
Le code précédent affiche ce résulat:
Accuracy: 1.0
[[ 19 0 0 ]
[ 0 13 0 ]
[ 0 0 13 ]]
[[ 19 0 0 ]
[ 0 13 0 ]
[ 0 0 13 ]]
Le modèle k-NN avec k=3 a obtenu une exéctitude parfaite (accuracy = 1.0) sur le jeu de test, ce qui signifie qu’il a correctement classé toutes les observations.
La matrice de confusion confirme cette performance (aucune erreur de classification entre les trois classes d’Iris). Ce résultat reflète une bonne séparation des classes dans les données. Néanmoins, il convient de rester prudent car une telle précision peut aussi indiquer un jeu de test trop simple ou les données de test sont trop proche des données d’entraînement.
Bien que ce code fonctionne sans prétraitement (preprocessing), il est fortement recommandé de normaliser les données avant d’utiliser un algorithme basé sur les distances comme k-NN. Cela permet d’éviter qu’une variable à grande échelle domine les autres. Nous verrons plus loin dans ce cours comment effectuer cette normalisation.
Leçon 14
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances

: un outil puissant de classification")
