Intelligence artificielle et Machine Learning: algorithmes et applications






Leçon 17: L'ensemble learning - Combiner plusieurs modèles pour une performance accrue
Toutes les leçons 
Intelligence artificielle et Machine Learning: algorithmes et applications
Leçon 14
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
Leçon 17
L'ensemble learning - Combiner plusieurs modèles pour une performance accrue
L'ensemble learning - Combiner plusieurs modèles pour une performance accrue
Renforcer la précision des modèles faibles grâce à l'ensemble learning
Qu'est ce que l'ensemble learning?
L’ensemble learning est une approche en intelligence artificielle qui repose sur l’idée de combiner plusieurs modèles afin d’obtenir une prédiction plus fiable et plus robuste qu’avec un modèle unique. Plutôt que de se fier à une seule source de décision, cette méthode agrège les résultats de différents algorithmes pour réduire les erreurs et améliorer la performance globale.L'ensemble learning permet notamment de limiter l’impact du surapprentissage (overfitting), de mieux gérer le bruit présent dans les données et d’augmenter la capacité de généralisation des systèmes. On peut imaginer l’ensemble learning comme un "comité d’experts" où chaque modèle apporte sa propre vision du problème. La combinaison de ces perspectives produit une décision finale plus équilibrée et plus précise. Cette approche est largement utilisée dans des domaines sensibles comme la finance, la santé ou la cybersécurité où la fiabilité des prédictions est essentielle
L’ensemble learning regroupe plusieurs méthodes qui visent à combiner différents modèles pour améliorer la précision et la robustesse des prédictions. Parmi les approches les plus utilisées, on distingue:
- Le boosting: qui entraîne les modèles de manière séquentielle afin que chacun corrige les erreurs du précédent.
- Le bagging: qui consiste à entraîner plusieurs modèles en parallèle sur des sous-échantillons des données
- Le stacking: qui combine les prédictions de plusieurs modèles de base grâce à un méta-modèle chargé de produire une décision finale plus fiable
Ces trois techniques illustrent différentes manières d’exploiter la diversité des modèles pour obtenir des résultats plus performants et réduire les erreurs.
Le boosting - Apprentissage séquentiel et itératif
Le boosting fonctionne de manière séquentielle où chaque nouveau modèle est entraîné pour corriger les erreurs commises par le précédent. L’idée est de donner plus de poids aux exemples mal classés afin que le système apprenne progressivement à mieux gérer les cas difficiles. Ce processus permet de réduire le biais et d’augmenter la précision, en particulier sur des données complexes ou bruitées.Cette illustration représente le processus du boosting où le modèle initial qui commence l’apprentissage. Ensuite, une série de modèles successifs corrigent les erreurs du modèle précédent. Le modèle final (qui est le plus robuste et le plus précis) est obtenu grâce à cette approche séquentielle.
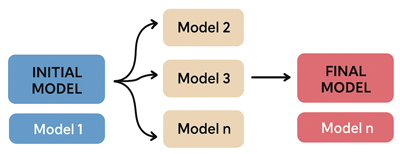
Les algorithmes de Boosting les plus connus sont:
- AdaBoost (Adaptive Boosting): l’un des premiers algorithmes de boosting, qui ajuste dynamiquement les poids des observations mal classées pour améliorer la performance globale.
- Gradient Boosting: une approche qui optimise les prédictions en minimisant une fonction de perte via des modèles successifs.
- XGBoost (Extreme Gradient Boosting): une version optimisée du gradient boosting et qui est très populaire en compétition de data science pour sa rapidité et son efficacité.
- LightGBM (Light Gradient Boosting Machine): développé par Microsoft, cet algorithme est conçu pour traiter de grands volumes de données avec une efficacité mémoire accrue.
- CatBoost: spécialisé dans le traitement des variables catégorielles, il réduit le besoin de prétraitement et améliore la performance sur des données hétérogènes.
Le boosting est particulièrement efficace pour les problèmes de classification et de régression et il est largement utilisé dans des domaines comme la finance (détection de fraude), la santé (diagnostic assisté), ou encore le marketing (prédiction du comportement client). Sa force réside dans sa capacité à transformer des modèles simples en systèmes puissants et fiables.
Le bagging (Bootstrap Aggregating)
Le bagging (Bootstrap Aggregating) est une technique d’ensemble learning qui vise à améliorer la stabilité et la précision des modèles en réduisant la variance. Son principe repose sur la création de plusieurs sous-ensembles de données obtenus par échantillonnage aléatoire avec remise (bootstrap). Ensuite des modèles indépendants sont entrainés sur ces sous-ensembles là.Chaque modèle du bagging produit sa propre prédiction qui sont ensuite agrégées par vote majoritaire (le plus souvent) pour la classification ou par moyenne pour la régression. Cette approche permet de limiter le surapprentissage (overfitting) et d’augmenter la robustesse du système, notamment lorsque les données sont bruitées ou instables.
Cette figure illustre le processus du bagging où les modèles indépendants (Model 1, Model 2, Model n) sont entraîné sur un sous-échantillon différent de données. Les prédictions sont ensuite aggrégées (par vote ou par moyenne).
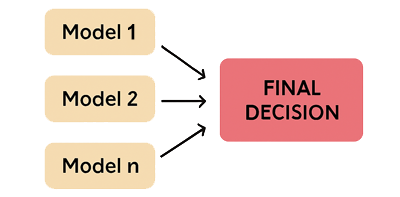
Les algorithmes de Boosting les plus connus sont:
- Random Forest: Sans doute le plus célèbre de tous. Il est basé sur une collection d’arbres de décision (decision tree) entraînés sur des sous-échantillons aléatoires des données et des variables.
- Extra Trees (Extremely Randomized Trees): Une variante du Random Forest où les seuils de séparation sont choisis de manière totalement aléatoire, ce qui augmente la diversité des arbres.
- Bagging SVM / Bagging KNN: Même s’ils sont moins répandus, ces modèles appliquent le bagging afin de stabiliser des algorithmes particulièrement sensibles aux fluctuations des données tels que les SVM ou le KNN.
Le stacking (stacked generalization)
Le stacking (ou stacked generalization) est une technique d’ensemble learning qui consiste à combiner plusieurs modèles de base à l’aide d’un méta-modèle chargé d’apprendre à fusionner leurs prédictions.Contrairement au bagging où les modèles sont agrégés par vote ou moyenne, le stacking repose sur une approche apprenante. En effet, le méta-modèle est entraîné sur les sorties des modèles de base pour optimiser la décision finale. Cette méthode permet de tirer parti de la diversité des algorithmes utilisés en exploitant leurs forces respectives pour améliorer la performance globale. Elle est particulièrement utile lorsque les modèles de base ont des comportements complémentaires (par exemple, certains sont bons pour les données linéaires et d’autres pour les interactions complexes).
L'illustration suivante représente une architecture de stacking où les modèles de base (Model 1, Model 2, Model n) sont placés en parallèle. Leurs sorties convergent vers un méta-modèle qui apprend à combiner ces prédictions pour produire une décision finale.
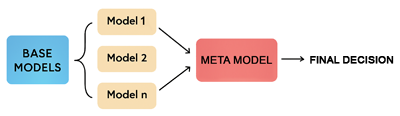
Contrairement au bagging et au boosting qui reposent sur des mécanismes bien définis d’échantillonnage ou de correction d’erreurs, le stacking n’est pas un algorithme en soi, mais une stratégie de combinaison. Il fonctionne comme un chef d’orchestre qui apprend à harmoniser les prédictions de plusieurs modèles de base en s’appuyant sur un méta-modèle pour produire une décision finale plus pertinente. Là où le bagging vote et le boosting corrige, le stacking apprend à choisir intelligemment parmi les voix disponibles.
Le stacking peut également intégrer des modèles à base de réseaux de neurones parmi les modèles de base ou comme méta-modèle.
Leçon 14
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
Leçon 17
L'ensemble learning - Combiner plusieurs modèles pour une performance accrue
L'ensemble learning - Combiner plusieurs modèles pour une performance accrue
")

