Intelligence artificielle et Machine Learning: algorithmes et applications






Leçon 26: Isolation Forest: identification des anomalies en apprentissage non supervisé
Toutes les leçons 
Intelligence artificielle et Machine Learning: algorithmes et applications
Leçon 14
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
Leçon 26
Isolation Forest: identification des anomalies en apprentissage non supervisé
Isolation Forest: identification des anomalies en apprentissage non supervisé
Détection d’anomalies avec les algorithmes non supervisés
Identifier les valeurs aberrantes présentes dans les données
La détection d’anomalies (traduite anomaly detection ou outlier identification) relève de l’apprentissage non supervisé où le modèle n’a pas besoin d’exemples pré-étiquetés pour distinguer le normal de l’atypique. C’est une tâche essentielle en science des données et en cybersécurité, puisqu’elle permet d’identifier des comportements ou des observations qui s’écartent fortement de la norme.Ces anomalies peuvent correspondre à des fraudes, des intrusions, des erreurs de saisie ou des phénomènes rares. L’objectif est de construire un modèle capable de différencier les points normaux (qui suivent une distribution attendue) des points atypiques (qui ne s’intègrent pas bien dans cette distribution).
Pour cela, plusieurs approches existent: des méthodes statistiques classiques (tests de distribution, scores de z...) jusqu’aux algorithmes d’apprentissage automatique comme l’Isolation Forest, qui exploitent des arbres aléatoires pour isoler plus rapidement les anomalies que les points réguliers.
Isolation Forest: identifier les comportements atypiques
Isolation Forest est un algorithme non supervisé particulièrement efficace. Son principe repose sur l’idée qu’une anomalie est plus facile à isoler qu’un point normal. L’algorithme construit de nombreux arbres binaires en choisissant aléatoirement des variables et des seuils de séparation. Les points atypiques, situés loin des concentrations de données, sont isolés en peu de divisions, tandis que les points normaux nécessitent davantage de partitions pour être séparés. En moyenne, si un point est isolé rapidement dans plusieurs arbres, il est considéré comme un outlier. Cette approche est rapide, scalable et bien adaptée aux grands ensembles de données.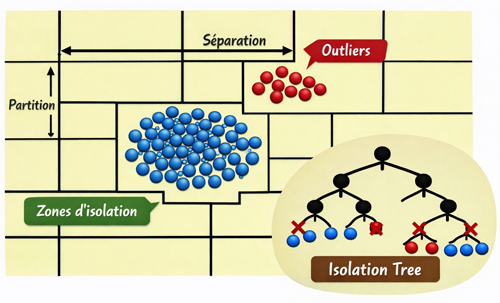
Isolation Forest: application concrète en détection d’anomalies
Cas d’étude: repérer les anomalies dans des données générées
Dans cet exemple, nous allons voir une mise en situation pratique pour illustrer comment l’algorithme Isolation Forest identifie automatiquement les valeurs atypiques dans un jeu de données simulé.Je propose le code suivante:
import numpy as np
import pandas as pd
from sklearn.ensemble import IsolationForest
import matplotlib.pyplot as plt
# Génération de données (points normaux + outliers)
rng = np.random.RandomState(42)
X_normal = 0.3 * rng.randn(100, 2)
X_outliers = rng.uniform(low=-4, high=4, size=(20, 2))
X = np.vstack((X_normal, X_outliers))
# Entraînement du modèle Isolation Forest
iso_forest = IsolationForest(
contamination=0.2,
random_state=42
)
y_pred = iso_forest.fit_predict(X)
df = pd.DataFrame(X, columns=["feature1", "feature2"])
df["prediction"] = y_pred
plt.figure(figsize=(8,6))
plt.scatter(df.loc[df["prediction"] == 1, "feature1"],
df.loc[df["prediction"] == 1, "feature2"],
c="blue", label="Normal", edgecolor="k")
plt.scatter(df.loc[df["prediction"] == -1, "feature1"],
df.loc[df["prediction"] == -1, "feature2"],
c="red", label="Outlier", edgecolor="k")
plt.title("Détection d'outliers avec Isolation Forest")
plt.xlabel("feature1")
plt.ylabel("feature2")
plt.legend()
plt.show()
Passons à l'explication du code.
import pandas as pd
from sklearn.ensemble import IsolationForest
import matplotlib.pyplot as plt
# Génération de données (points normaux + outliers)
rng = np.random.RandomState(42)
X_normal = 0.3 * rng.randn(100, 2)
X_outliers = rng.uniform(low=-4, high=4, size=(20, 2))
X = np.vstack((X_normal, X_outliers))
# Entraînement du modèle Isolation Forest
iso_forest = IsolationForest(
contamination=0.2,
random_state=42
)
y_pred = iso_forest.fit_predict(X)
df = pd.DataFrame(X, columns=["feature1", "feature2"])
df["prediction"] = y_pred
plt.figure(figsize=(8,6))
plt.scatter(df.loc[df["prediction"] == 1, "feature1"],
df.loc[df["prediction"] == 1, "feature2"],
c="blue", label="Normal", edgecolor="k")
plt.scatter(df.loc[df["prediction"] == -1, "feature1"],
df.loc[df["prediction"] == -1, "feature2"],
c="red", label="Outlier", edgecolor="k")
plt.title("Détection d'outliers avec Isolation Forest")
plt.xlabel("feature1")
plt.ylabel("feature2")
plt.legend()
plt.show()
On commence par importer la classe IsolationForest depuis le module sklearn.ensemble afin de l’utiliser pour entraîner notre modèle de détection d’anomalies.
from sklearn.ensemble import IsolationForest
D’autres modules couramment utilisés ont également été importés afin de construire un pipeline complet en data science.
Ensuite, on génère un jeu de données synthétique composé de points normaux et de valeurs aberrantes:
rng = np.random.RandomState(42)
X_normal = 0.3 * rng.randn(100, 2)
X_outliers = rng.uniform(low=-4, high=4, size=(20, 2))
X = np.vstack((X_normal, X_outliers))
rng = np.random.RandomState(42) fixe une graine aléatoire pour assurer la reproductibilité de l'expérience.
X_normal = 0.3 * rng.randn(100, 2)
X_outliers = rng.uniform(low=-4, high=4, size=(20, 2))
X = np.vstack((X_normal, X_outliers))
X_normal = 0.3 * rng.randn(100, 2) crée 100 points centrés autour de zéro, simulant des données normales.
X_outliers = rng.uniform(low=-4, high=4, size=(20, 2)) génère 20 points dispersés dans une zone beaucoup plus large, représentant des anomalies.
X = np.vstack((X_normal, X_outliers)) assemble les deux ensembles en une seule matrice pour l’analyse.
Puis on entraîne et applique l’algorithme Isolation Forest sur le jeu de données:
iso_forest = IsolationForest(
contamination=0.2,
random_state=42
)
y_pred = iso_forest.fit_predict(X)
contamination=0.2,
random_state=42
)
y_pred = iso_forest.fit_predict(X)
iso_forest = IsolationForest(contamination=0.2, random_state=42) crée un modèle en supposant que 20% des points sont des anomalies.
y_pred = iso_forest.fit_predict(X) entraîne le modèle sur X et renvoie une prédiction (1 pour les points considérés comme normaux et -1 pour les points détectés comme outliers).
Dans scikit‑learn, la méthode fit_predict() de l’algorithme Isolation Forest renvoie par défaut les valeurs 1 (points normaux) et -1 (anomalies).
Après, on transforme le jeu de données en un DataFrame pandas pratique:
df = pd.DataFrame(X, columns=["feature1", "feature2"])
df["prediction"] = y_pred
df = pd.DataFrame(X, columns=["feature1", "feature2"]) crée une table avec deux colonnes représentant les variables.
df["prediction"] = y_pred
df["prediction"] = y_pred ajoute une colonne supplémentaire indiquant la classification par Isolation Forest (1 = normal, -1 = anomalie).
Enfin, on produit une visualisation claire des résultats d’Isolation Forest: les points normaux (prediction == 1) sont affichés en bleu et les outliers (prediction == -1) apparaissent en rouge:
plt.figure(figsize=(8,6))
plt.scatter(df.loc[df["prediction"] == 1, "feature1"],
df.loc[df["prediction"] == 1, "feature2"],
c="blue", label="Normal", edgecolor="k")
plt.scatter(df.loc[df["prediction"] == -1, "feature1"],
df.loc[df["prediction"] == -1, "feature2"],
c="red", label="Outlier", edgecolor="k")
plt.title("Détection d'outliers avec Isolation Forest")
plt.xlabel("feature1")
plt.ylabel("feature2")
plt.legend()
plt.show()
Après exécution du code, on obtient cette illustration:
plt.scatter(df.loc[df["prediction"] == 1, "feature1"],
df.loc[df["prediction"] == 1, "feature2"],
c="blue", label="Normal", edgecolor="k")
plt.scatter(df.loc[df["prediction"] == -1, "feature1"],
df.loc[df["prediction"] == -1, "feature2"],
c="red", label="Outlier", edgecolor="k")
plt.title("Détection d'outliers avec Isolation Forest")
plt.xlabel("feature1")
plt.ylabel("feature2")
plt.legend()
plt.show()
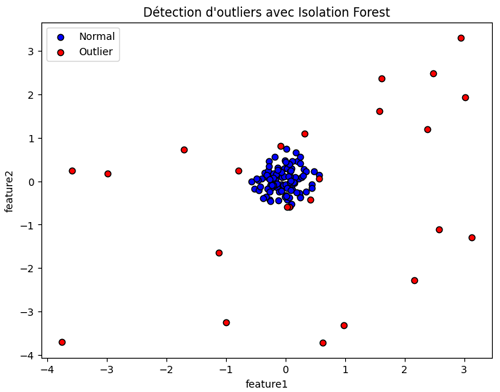
Ce graphique illustre comment Isolation Forest sépare les données normales des anomalies en créant des zones de partition. Les points bleus regroupés représentent les observations régulières, tandis que les points rouges isolés indiquent des comportements atypiques.
Cette visualisation met en évidence l’utilité d’Isolation Forest pour repérer efficacement les valeurs aberrantes dans de grands ensembles de données, ce qui représente un atout majeur en data science et en cybersécurité.
Leçon 14
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
Leçon 26
Isolation Forest: identification des anomalies en apprentissage non supervisé
Isolation Forest: identification des anomalies en apprentissage non supervisé


