Intelligence artificielle et Machine Learning: algorithmes et applications






Leçon 27: Analyse en Composantes Principales PCA: Réduction de dimension non supervisée
Toutes les leçons 
Intelligence artificielle et Machine Learning: algorithmes et applications
Leçon 14
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
Leçon 27
Analyse en Composantes Principales PCA: Réduction de dimension non supervisée
Analyse en Composantes Principales PCA: Réduction de dimension non supervisée
Simplifier sans perdre l’information avec PCA
PCA: Principal Component Analysis
La PCA (Principal Component Analysis ou Analyse en Composantes Principales) est une technique statistique de réduction de dimension utilisée en apprentissage non supervisé. Elle consiste à transformer un ensemble de variables initiales, souvent corrélées entre elles, en un nouvel ensemble de variables non corrélées appelées composantes principales. Ces composantes sont ordonnées de façon à ce que les premières capturent la plus grande part de la variance des données. L’idée est donc de condenser l’information en quelques axes tout en minimisant la perte d’information, ce qui facilite la visualisation, l’analyse et parfois améliore l’efficacité des modèles de machine learning.Dans la pratique, PCA calcule la matrice de covariance des données, puis en extrait les vecteurs propres (directions principales) et les valeurs propres (importance de chaque direction). Les données sont ensuite projetées sur ces axes principaux. Par exemple, dans le dataset Iris (4 variables initiales), PCA permet de réduire à 2 dimensions tout en conservant l’essentiel de la variance. Cette projection rend visible la structure des données et montre que les espèces d’Iris se distinguent naturellement, ce qui illustre la puissance de PCA pour révéler des patterns cachés.
PCA appliquée au dataset Iris: réduction de dimension et visualisation
Dans le cas du dataset Iris, on dispose de 4 variables (longueur et largeur des sépales et pétales), ce qui rend leur visualisation simultanée difficile. L’Analyse en Composantes Principales (PCA) permet de projeter ces données dans un espace de dimension réduite en cherchant les axes qui capturent le maximum de variance.En ramenant les 4 dimensions initiales à seulement 2 composantes principales, on obtient une représentation plus simple et lisible, tout en conservant l’essentiel de l’information. Cette réduction facilite la visualisation et révèle la structure des données, notamment la séparation naturelle entre les différentes espèces d’Iris.
Je propose le code suivante:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
iris = load_iris()
X = iris.data
y = iris.target
# Normalisation de données (important pour PCA)
X_scaled = StandardScaler().fit_transform(X)
# Appliquer PCA (réduction à 2 dimensions)
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# Visualiser les données projetées
plt.figure(figsize=(8,6))
for target in np.unique(y):
plt.scatter(
X_pca[y == target, 0],
X_pca[y == target, 1],
label=iris.target_names[target]
)
plt.xlabel("Composante principale 1")
plt.ylabel("Composante principale 2")
plt.title("Projection PCA du dataset Iris")
plt.legend()
plt.show()
# Variance expliquée par chaque composante
print("Variance expliquée :", pca.explained_variance_ratio_)
Après avoir importé les modules nécessaire, il est essentielle de normaliser les données en PCA, car elle met toutes les variables sur la même échelle (moyenne = 0, variance = 1 dans ce cas):
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
iris = load_iris()
X = iris.data
y = iris.target
# Normalisation de données (important pour PCA)
X_scaled = StandardScaler().fit_transform(X)
# Appliquer PCA (réduction à 2 dimensions)
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# Visualiser les données projetées
plt.figure(figsize=(8,6))
for target in np.unique(y):
plt.scatter(
X_pca[y == target, 0],
X_pca[y == target, 1],
label=iris.target_names[target]
)
plt.xlabel("Composante principale 1")
plt.ylabel("Composante principale 2")
plt.title("Projection PCA du dataset Iris")
plt.legend()
plt.show()
# Variance expliquée par chaque composante
print("Variance expliquée :", pca.explained_variance_ratio_)
X_scaled = StandardScaler().fit_transform(X)
Sans cette normalisation (Z‑score normalization), les variables ayant de grandes amplitudes numériques domineraient le calcul des composantes principales, ce qui fausserait la projection. En standardisant les données, la PCA peut identifier les axes qui reflètent réellement la variance structurelle du jeu de données plutôt que simplement la différence d’unités ou de grandeurs.
Ensuite, on procède à la réduction de dimensions en PCA:
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
Ici, on demande à la PCA de conserver seulement 2 composantes principales. Le modèle calcule les axes qui expliquent le maximum de variance dans les données normalisées X_scaled et projette chaque observation sur ces deux axes.
X_pca = pca.fit_transform(X_scaled)
Le résultat X_pca est donc une version condensée du dataset initial: au lieu de 4 dimensions (longueur/largeur sépales et pétales), on obtient 2 dimensions qui concentrent l’essentiel de l’information. Cela facilite la visualisation et met en évidence les structures latentes, comme la séparation naturelle entre les espèces d’Iris.
En fin, on projette les données sur ces deux composantes:
plt.figure(figsize=(8,6))
for target in np.unique(y):
plt.scatter(
X_pca[y == target, 0],
X_pca[y == target, 1],
label=iris.target_names[target]
)
plt.xlabel("Composante principale 1")
plt.ylabel("Composante principale 2")
plt.title("Projection PCA du dataset Iris")
plt.legend()
plt.show()
On obtient une représentation 2D où les espèces d’Iris apparaissent relativement séparées, ce qui illustre comment la PCA permet de révéler la structure cachée des données tout en réduisant leur complexité.
for target in np.unique(y):
plt.scatter(
X_pca[y == target, 0],
X_pca[y == target, 1],
label=iris.target_names[target]
)
plt.xlabel("Composante principale 1")
plt.ylabel("Composante principale 2")
plt.title("Projection PCA du dataset Iris")
plt.legend()
plt.show()
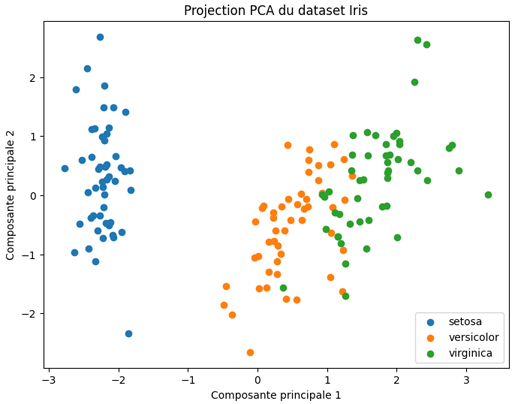
Dans ce graphique, les axes Composante principale 1 et Composante principale 2 correspondent aux deux directions de variance maximale trouvées par la PCA.
- Composante principale 1 (PC1): est l’axe qui capture la plus grande part de la variance des données. Dans le cas d’Iris, il combine linéairement les quatre variables (longueur/largeur sépales et pétales) pour former une nouvelle dimension qui explique le maximum de différences entre les fleurs.
- Composante principale 2 (PC2): est l’axe orthogonal au premier, qui capture la deuxième plus grande part de variance restante. Il complète PC1 pour donner une vue en deux dimensions qui conserve l’essentiel de l’information.
On affiche également la proportion de variance capturée par chaque composante principale:
print("Variance expliquée :", pca.explained_variance_ratio_)
En PCA, c’est un indicateur crucial: il permet de savoir combien d’information des données originales est conservée dans les nouvelles dimensions.
Variance expliquée : [0.72962445 0.22850762]
On voit que la Composante principale 1 explique environ 73% de la variance totale, tandis que la Composante principale 2 en explique environ 23%. Cela signifie qu’en réduisant les 4 dimensions initiales du dataset Iris à seulement 2 axes, on conserve plus de 96% de l’information.
Cette forte proportion justifie pleinement l’utilisation de la PCA: la projection en deux dimensions reste représentative des données originales et permet de visualiser clairement la structure et la séparation entre les espèces d’Iris, tout en simplifiant l’analyse.
Leçon 14
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
k-Nearest Neighbors (k-NN): Algorithme de classification non paramétrique basé sur les distances
Leçon 27
Analyse en Composantes Principales PCA: Réduction de dimension non supervisée
Analyse en Composantes Principales PCA: Réduction de dimension non supervisée


