Deep Learning: comprendre et construire des réseaux de neurones






Leçon 23: Transformers: une architecture moderne et flexible
Toutes les leçons 
Deep Learning: comprendre et construire des réseaux de neurones
Leçon 17
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Leçon 23
Transformers: une architecture moderne et flexible
Transformers: une architecture moderne et flexible
Dans cette leçon consacrée au Deep Learning, nous traiterons un exemple appliqué au texte (donc relevant du NLP) afin d’illustrer concrètement le fonctionnement des Transformers. Bien que ce cours ne soit pas centré sur le NLP, il est important de rappeler que les Transformers sont aujourd’hui largement utilisés dans ce domaine où ils ont révolutionné les approches modernes.
Les Transformers: une architecture pensée pour la parallélisation
Une architecture sans récurrence: rupture avec la séquence pas à pas
Les réseaux de neurones récurrents traitent les données mot après mot en suivant l’ordre de la séquence. Cette approche imite la lecture humaine, mais elle impose une contrainte. En effet, chaque étape dépend de la précédente, ce qui ralentit le calcul et limite la capacité à exploiter de grandes quantités de données.Les Transformers, eux, abandonnent complètement cette logique séquentielle. Plutôt que de parcourir la phrase pas à pas, ils utilisent deux outils clés:
- Le self-attention: qui permet au modèle de relier directement chaque mot aux autres, peu importe leur position.
- L’encodage positionnel: qui ajoute une information sur l’ordre des mots afin de ne pas perdre la structure de la phrase.
Grâce à cette conception, le traitement devient parallèle et le modèle peut analyser tous les mots en même temps au lieu d’attendre la fin d’une boucle. Cette parallélisation accélère considérablement l’entraînement et rend possible l’utilisation de corpus massifs, ce qui était difficile avec les architectures récurrentes.
L’architecture des Transformers est aujourd’hui au cœur des modèles de langage les plus emblématiques, tels que GPT, Claude, Gemini, DeepSeek ou Mistral. Chacun ayant introduit de légères adaptations, mais reposant toujours sur les mêmes principes fondamentaux de parallélisation et de mécanismes d’attention.
Dans cette même leçon, nous allons détailler les concepts fondamentaux de l’architecture des Transformers y compris le self-attention et l'encodage prositionnel.
Architecture des Transformers: principes et composition
Transformers: Une architecture neuronale modernisée
Les Transformers ne sont pas une rupture totale avec le paradigme des réseaux de neurones. En réalité, ils en demeurent une architecture fondée sur des couches et des calculs matriciels comme les modèles classiques. Ce qui les distingue, c’est l’intégration de mécanismes avancés qui élargissent considérablement leurs capacités.Nous présentons ici deux représentations de l’architecture des Transformers: la version originale issue de l’article Attention Is All You Need, et une version simplifiée conçue pour faciliter la compréhension des mécanismes essentiels avant d’entrer dans les détails techniques:
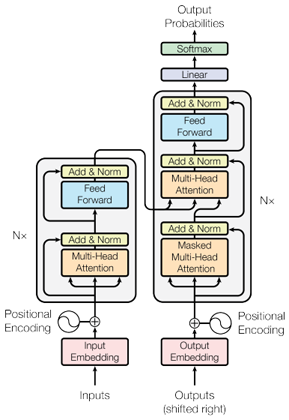
Version originale de l'architecture des Transformers - Source
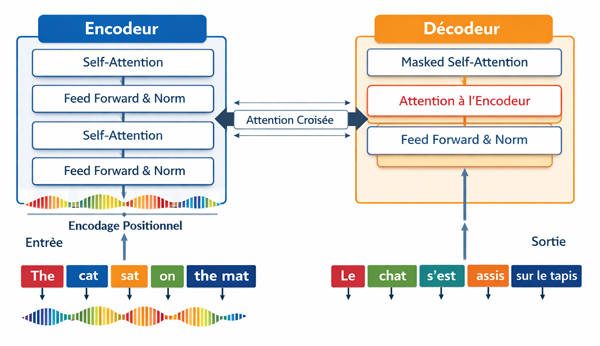
Version simplifiée pour faciliter la compréhension
Vous trouverez les détails techniques du schéma original de l’article Attention Is All You Need.
Structure encodeur–décodeur
Un Transformer est avant tout une architecture de réseau de neurones organisée autour de deux blocs principaux:- L’encodeur: il reçoit la séquence d’entrée et en construit une représentation riche grâce au mécanisme de self-attention. Chaque élément de la séquence peut ainsi se relier directement aux autres, ce qui permet de capturer des dépendances locales et globales en une seule opération.
- Le décodeur: il génère la séquence de sortie (par exemple une traduction), en combinant deux sources d’information: son propre self-attention et l’attention croisée vers l’encodeur. Cela lui permet de produire un texte cohérent tout en restant fidèle au contenu initial.
Cette séparation encodeur–décodeur rend l’architecture flexible et puissante, adaptée à de nombreuses tâches comme la traduction automatique, le résumé de documents ou la génération de texte. Elle constitue la base sur laquelle reposent les modèles modernes de grande taille.
Le rôle du self-attention
Le mécanisme de self-attention permet à chaque mot d’une séquence de "regarder" directement tous les autres mots et de pondérer leur importance en fonction du contexte. Contrairement aux modèles séquentiels classiques, il n’est pas limité par un parcours mot à mot.Prenons l’exemple "The cat sat on the mat":
Le mot "cat" peut établir un lien direct avec "sat", car ce verbe est essentiel pour comprendre l’action. Le modèle n’a pas besoin de suivre un chemin séquentiel pas à pas: il capture cette relation immédiatement. Ainsi, le self-attention saisit à la fois les relations locales ("cat" ↔ "sat") et les relations globales ("cat" ↔ "mat") en une seule opération.
Ce fonctionnement rend l’architecture Transformer capable de traiter efficacement des dépendances complexes, qu’elles soient proches ou éloignées dans la phrase.
Je vous invite à consulter cette leçon sur le mécanisme d'attention pour plus de détails.
Multi-head attention et richesse des relations
Le Transformer ne se limite pas à une seule "vue" de la séquence. Grâce au multi-head attention, il calcule plusieurs représentations en parallèle. Chaque "tête" (head) d’attention se concentre sur un type de relation particulier. Certaines captent des liens syntaxiques (par exemple la relation sujet–verbe), d’autres mettent en évidence des aspects sémantiques (le sens des mots dans le contexte), d’autres encore détectent des dépendances longues entre des éléments éloignés dans la phrase...En combinant ces différentes perspectives, le modèle obtient une compréhension beaucoup plus riche et nuancée de la séquence. C’est cette capacité à analyser simultanément plusieurs dimensions du langage qui rend les Transformers si puissants pour des tâches complexes comme la traduction, le résumé ou la génération de texte.
Normalisation et feed-forward
Chaque bloc du Transformer ne se limite pas aux mécanismes d’attention. Il intègre également deux composants essentiels:- Les couches de normalisation (Layer Normalization): elles stabilisent l’entraînement en réduisant les variations trop fortes dans les activations. Cela permet au modèle de converger plus rapidement et d’éviter les dérives numériques.
- Les réseaux feed-forward: ce sont de petits réseaux entièrement connectés appliqués à chaque position indépendamment. Ils ajoutent de la capacité de modélisation en permettant au modèle de transformer les représentations issues de l’attention et d’apprendre des relations plus complexes.
En combinant ces éléments avec l’attention, le Transformer reste robuste et performant, même sur des données volumineuses et variées.
Impact et applications des Transformers
Des variantes emblématiques: BERT, GPT, T5, ViT
Les Transformers ont donné naissance à une variété de modèles emblématiques, chacun exploitant différemment l’encodeur et le décodeur.Par exemple, BERT repose uniquement sur l’encodeur pour produire des représentations contextuelles puissantes, tandis que GPT utilise exclusivement le décodeur pour la génération de texte. Des modèles comme T5 combinent les deux blocs dans une architecture encodeur–décodeur complète, adaptée à des tâches variées comme la traduction ou le résumé. Enfin, les Vision Transformers (ViT) appliquent le principe de l’encodeur au domaine de la vision par ordinateur.
Ces déclinaisons ont transformé le NLP et la vision par ordinateur, établissant les Transformers comme la référence incontournable des tâches modernes d’IA.
Leçon 17
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Leçon 23
Transformers: une architecture moderne et flexible
Transformers: une architecture moderne et flexible

