Deep Learning: comprendre et construire des réseaux de neurones






Leçon 18: LSTM: Long Short-Term Memory - une mémoire longue durée pour les séquences
Toutes les leçons 
Deep Learning: comprendre et construire des réseaux de neurones
Leçon 17
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Leçon 18
LSTM: Long Short-Term Memory - une mémoire longue durée pour les séquences
LSTM: Long Short-Term Memory - une mémoire longue durée pour les séquences
La mémoire longue durée au cœur des LSTM
LSTM: Long Short-Term Memory
Dans la leçon précédente sur les limites des RNN face aux dépendances longues, nous avons vu que les RNN classiques souffrent du problème du vanishing gradient. Lors de l’entraînement par rétropropagation à travers le temps, les gradients deviennent de plus en plus petits au fil des étapes, ce qui empêche le réseau d’apprendre efficacement les dépendances à long terme. En pratique, cela signifie que les RNN simples mémorisent bien des séquences courtes, mais échouent dès qu’il s’agit de conserver une information sur plusieurs dizaines ou centaines de pas temporels.C’est précisément pour répondre à cette limite que les LSTM (Long Short-Term Memory) ont été introduits. Grâce à leur architecture interne, les LSTM parviennent à préserver et exploiter des dépendances sur de longues séquences. Ils atténuent ainsi le problème du vanishing gradient et permettent d’aborder des tâches complexes qui invoquent la notion de pas de temps (time step).
Les LSTM (Long Short-Term Memory) sont une architecture particulière de réseaux de neurones récurrents introduite en 1997 par Sepp Hochreiter et Jürgen Schmidhuber (dans un article fondateur publié dans la revue Neural Computation. Leur conception visait à résoudre le problème majeur du vanishing gradient rencontré dans les RNN classiques, qui limitaient l’apprentissage des dépendances à long terme. Les LSTM se distinguent par l’ajout d’un mécanisme de mémoire interne et de portes de contrôle (oubli, entrée, sortie) permettant de réguler le flux d’information. Grâce à cette structure, ils peuvent conserver et exploiter des informations sur de longues séquences, ce qui les rend particulièrement adaptés aux tâches complexes comme la traduction automatique, la reconnaissance vocale ou l’analyse de séries temporelles .
Décomposition d'une cellule LSTM
Une cellule LSTM se distingue par sa capacité à gérer l’information grâce à quatre mécanismes principaux: la porte d’oubli, la porte d’entrée, la mise à jour de l’état de cellule et la porte de sortie. Ces portes fonctionnent comme des filtres intelligents, utilisant des fonctions sigmoïdes et tangentes hyperboliques pour contrôler le flux d’information. L’idée est de permettre au réseau de décider ce qu’il doit conserver, oublier, ajouter ou transmettre, afin de maintenir une mémoire stable sur de longues séquences.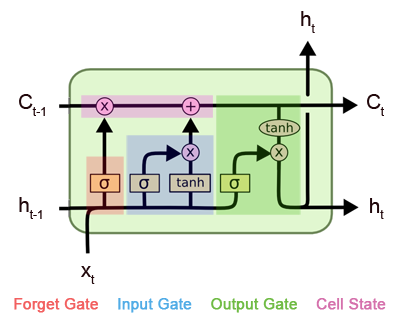
La porte d’oubli (Forget Gate)
La porte d’oubli est responsable de décider quelles informations de l’état précédent doivent être effacées. Elle prend en entrée l’état caché précédent \(h_{t-1}\) et l’entrée actuelle \(x_t\), puis applique une fonction sigmoïde:
\(f_t=\sigma (W_f\cdot [h_{t-1},x_t]+b_f)\)
Le résultat \(f_t\) est un vecteur de valeurs comprises entre 0 et 1. Une valeur proche de 0 signifie que l’information correspondante sera oubliée, tandis qu’une valeur proche de 1 indique qu’elle sera conservée. Cette étape est cruciale pour éviter que la mémoire ne sature avec des données inutiles.
La porte d’entrée (Input Gate)
La porte d’entrée contrôle quelles nouvelles informations doivent être ajoutées à la mémoire interne. Elle fonctionne en deux étapes:\(i_t=\sigma (W_i\cdot [h_{t-1},x_t]+b_i)\)
\(\tilde {C}_t=\tanh (W_C\cdot [h_{t-1},x_t]+b_C)\)
La première équation \((i_t)\) détermine, via une sigmoïde, quelles composantes seront mises à jour. La seconde \((\tilde {C}_t)\) génère des valeurs candidates pour enrichir la mémoire, normalisées entre -1 et 1 grâce à la fonction tanh. Ensemble, elles permettent d’ajouter de nouvelles informations pertinentes tout en filtrant ce qui doit entrer.
Mise à jour de l’état de cellule (Cell State)
L’état de cellule \(C_t\) est le cœur de la mémoire longue durée. Il est mis à jour en combinant l’oubli et l’ajout d’informations nouvelles:\(C_t=f_t\cdot C_{t-1}+i_t\cdot \tilde {C}_t\)
Cette équation illustre l’équilibre entre la suppression des données obsolètes \((f_t\cdot C_{t-1})\) et l’intégration des nouvelles informations \((i_t\cdot \tilde {C}_t)\). Le résultat est une mémoire interne stable, capable de transporter des informations sur de longues séquences sans subir le vanishing gradient.
La porte de sortie (Output Gate)
Enfin, la porte de sortie détermine quelle partie de la mémoire interne doit influencer la sortie actuelle. Elle calcule un filtre sigmoïde:\(o_t=\sigma (W_o\cdot [h_{t-1},x_t]+b_o)\)
Puis génère la sortie cachée:
\(h_t=o_t\cdot \tanh (C_t)\)
Ainsi, la sortie \(h_t\) est une combinaison de l’état interne \(C_t\) et du filtre \(o_t\). Cela permet au réseau de produire une information pertinente pour la tâche en cours, tout en maintenant une mémoire intacte pour les étapes suivantes.
En résumé, une cellule LSTM transforme une séquence en traitant chaque élément étape par étape tout en conservant une mémoire interne. À chaque instant, elle décide ce qu’elle doit oublier, ajouter, et transmettre grâce à ses portes de contrôle.
Contrairement aux RNN classiques qui perdent rapidement l’information, la LSTM maintient une trace des éléments importants sur toute la séquence, ce qui lui permet de comprendre le contexte global et de produire des sorties cohérentes, même lorsque les dépendances sont éloignées dans le temps.
Lors de la prochaine leçon, nous passerons à un cas pratique avec du code Python pour illustrer concrètement comment une cellule LSTM transforme une séquence en sortie. Cela permettra de mieux comprendre le fonctionnement interne des portes et de visualiser l’impact de la mémoire sur les prédictions.
Leçon 17
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Leçon 18
LSTM: Long Short-Term Memory - une mémoire longue durée pour les séquences
LSTM: Long Short-Term Memory - une mémoire longue durée pour les séquences


