Deep Learning: comprendre et construire des réseaux de neurones






Leçon 20: GRU: Gated Recurrent Unit - vers une simplification des architectures récurrentes
Toutes les leçons 
Deep Learning: comprendre et construire des réseaux de neurones
Leçon 17
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Leçon 20
GRU: Gated Recurrent Unit - vers une simplification des architectures récurrentes
GRU: Gated Recurrent Unit - vers une simplification des architectures récurrentes
GRU: Gated Recurrent Unit
De la complexité des LSTM vers la simplicité des GRU
Après avoir étudié les LSTM (Long Short-Term Memory) qui apportent une réponse solide au problème du vanishing gradient grâce à leur mécanisme de mémoire élaboré, nous allons nous tourner vers une autre déclinaison des réseaux récurrents: le GRU.Introduit en 2014 dans l'article intitulé Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation, le GRU (Gated Recurrent Unit) se distingue par une architecture plus épurée que celle du LSTM tout en préservant la capacité à capturer des dépendances temporelles étendues dans les séquences. Cette simplification structurelle en fait une solution particulièrement pertinente dans les contextes où il est nécessaire de concilier performance et efficacité computationnelle.
Décomposition d'une cellule GRU
Le Gated Recurrent Unit (GRU) repose sur une architecture simplifiée par rapport au LSTM, mais conserve la capacité de gérer des dépendances temporelles longues. Une cellule GRU se compose essentiellement de deux portes: la porte de mise à jour (update gate) et la porte de réinitialisation (reset gate). Ces mécanismes permettent de contrôler le flux d’information entre l’état précédent et l’état courant sans nécessiter une cellule mémoire distincte.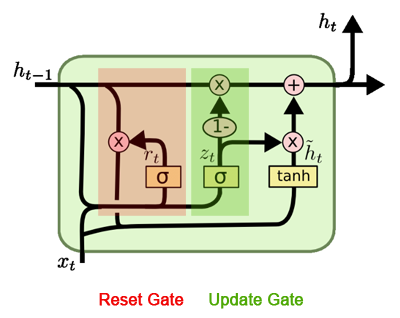
La porte de mise à jour (update gate)
La porte de mise à jour détermine la proportion d’information ancienne à conserver et celle à remplacer par de nouvelles données. Mathématiquement, elle est définie par:\(z_t=\sigma (W_z\cdot x_t+U_z\cdot h_{t-1})\)
où:
- \(z_t\) est le vecteur de mise à jour
- \(x_t\) représente l’entrée au temps t
- \(h_{t-1}\) est l’état caché précédent
- \(W_z\) et \(U_z\) sont des matrices de poids
- \(\sigma\) est la fonction sigmoïde
Cette porte agit comme un régulateur: si \(z_t\) est proche de 1, l’information passée est largement conservée et si \(z_t\) est proche de 0, l’état est fortement renouvelé.
La porte de réinitialisation (reset gate)
La porte de réinitialisation contrôle la manière dont l’état précédent influence la nouvelle information. Elle est donnée par:\(r_t=\sigma (W_r\cdot x_t+U_r\cdot h_{t-1})\)
où \(r_t\) est le vecteur de réinitialisation.
Lorsque \(r_t\) tend vers 0, l’état passé est largement ignoré, ce qui permet au réseau de se concentrer sur l’entrée courante. À l’inverse, des valeurs proches de 1 favorisent une forte dépendance à l’historique.
Calcul de l’état candidat et de l’état final
Une fois les portes définies, le GRU calcule un état candidat \(\tilde {h}_t\):\(\tilde {h}_t=\tanh (W_h\cdot x_t+U_h\cdot (r_t\odot h_{t-1}))\)
où \(\odot\) désigne le produit élément par élément.
Cet état candidat intègre l’entrée actuelle et une version filtrée de l’état précédent.
Enfin, l’état caché final est obtenu par interpolation entre l’ancien état et le nouvel état candidat :
\(h_t=(1-z_t)\odot h_{t-1}+z_t\odot \tilde {h}_t\)
Ainsi, le GRU combine de manière adaptative mémoire et nouveauté, garantissant un équilibre entre stabilité et flexibilité dans le traitement des séquences.
Avantages computationnels et applications des GRU
Comparés aux LSTM, les GRU présentent une architecture plus compacte, ce qui se traduit par un nombre réduit de paramètres à entraîner. Cette simplification diminue la charge computationnelle et accélère l’apprentissage tout en limitant le risque de surapprentissage. De plus, l’absence de cellule mémoire distincte rend les calculs plus rapides et moins coûteux en ressources, ce qui est particulièrement avantageux dans des environnements contraints comme les applications mobiles ou les systèmes embarqués.Grâce à leur efficacité et leur capacité à capturer des dépendances temporelles longues, les GRU sont largement utilisés dans des domaines variés. On les retrouve dans la modélisation du langage naturel (traduction automatique, génération de texte), la reconnaissance vocale, la prédiction de séries temporelles (finance, météo, consommation énergétique), ainsi que dans des applications créatives comme la génération musicale. Leur équilibre entre performance et rapidité en fait une solution privilégiée lorsque les contraintes de calcul et de mémoire sont fortes, sans sacrifier la qualité des résultats.
Leçon 17
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Leçon 20
GRU: Gated Recurrent Unit - vers une simplification des architectures récurrentes
GRU: Gated Recurrent Unit - vers une simplification des architectures récurrentes


