Deep Learning: comprendre et construire des réseaux de neurones






Leçon 21: Analyse des séries temporelles de consommation électrique domestique par réseaux GRU
Toutes les leçons 
Deep Learning: comprendre et construire des réseaux de neurones
Leçon 17
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Leçon 21
Analyse des séries temporelles de consommation électrique domestique par réseaux GRU
Analyse des séries temporelles de consommation électrique domestique par réseaux GRU
Modélisation prédictive de la puissance active par réseaux GRU
Cette fois, nous allons traiter un cas réel en travaillant sur un dataset de consommation électrique domestique. Il s'agit d'un jeu de données complexe et réaliste qui reflète des mesures minutées sur plusieurs années. Cela nous permet de sortir des exemples simplifiés et de plonger dans une situation concrète, où la richesse et la granularité des données mettent en évidence les défis pratiques de la modélisation des séries temporelles avec des architectures comme les GRU.Household Electric Power Consumption Dataset
Le Household Electric Power Consumption Dataset (disponible sur Kaggle) est un jeu de données de référence en séries temporelles, collecté dans une maison située en France entre décembre 2006 et novembre 2010. Il contient plus de 2 millions d’enregistrements, mesurés chaque minute, ce qui en fait une ressource riche pour l’étude de la consommation énergétique domestique.Les variables principales sont :
- Global_active_power: puissance active totale consommée (en kilowatts).
- Global_reactive_power: puissance réactive (en kilowatts).
- Voltage: tension électrique (en volts).
- Global_intensity: intensité du courant (en ampères).
- Sub_metering_1, 2, 3: compteurs partiels correspondant à différents usages (cuisine, buanderie, chauffage/climatisation).
Ce dataset est particulièrement intéressant car :
- Il permet d’analyser les patterns journaliers et saisonniers de consommation.
- Il est adapté aux modèles séquentiels comme GRU ou LSTM, qui capturent les dépendances temporelles.
- Il peut être utilisé pour des tâches variées : prévision de la consommation, détection d’anomalies, ou encore optimisation énergétique.
Le Household Electric Power Consumption Dataset est un jeu de données réaliste, volumineux et multivarié, qui illustre parfaitement les défis de la modélisation des séries temporelles en énergie.
Modéliser les dynamiques temporelles de consommation électrique à l’aide d’une architecture GRU
Nous allons procéder à une agrégation des données par heure et retenir uniquement 100 000 échantillons afin d’accélérer l’entraînement du modèle GRU. Cette simplification permet de réduire le temps de calcul, mais elle peut entraîner une perte de précision dans les prédictions puisque certaines variations fines (au niveau minute) sont lissées. Il s’agit donc d’un exemple explicatif destiné à illustrer la démarche et non une optimisation finale. Dans un contexte réel, l’utilisation d’un GPU ou de techniques de parallélisation permettrait d’accélérer considérablement le traitement tout en conservant l’intégralité du dataset pour des résultats plus robustes.Je présenterai d’abord le code complet, puis j’en détaillerai les différents blocs étape par étape:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import GRU, Dense
from tensorflow.keras.optimizers import Adam
# Charger le dataset
df = pd.read_csv(
"household_power_consumption.csv", sep=';',
parse_dates={'datetime':['Date','Time']},
infer_datetime_format=True,
na_values='?',
low_memory=False
)
# Limiter à 100 000 lignes pour un test rapide
df = df.head(100000)
# Mettre datetime comme index
df = df.set_index('datetime')
# Agréger les mesures par heure
df = df.resample('H').mean().dropna()
# Garder uniquement Global_active_power
df = df[['Global_active_power']].dropna()
df['Global_active_power'] = df['Global_active_power'].astype(float)
# Normalisation
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(
df['Global_active_power'].values.reshape(-1,1)
)
# Création des séquences
def create_sequences(data, seq_length):
xs, ys = [], []
for i in range(len(data) - seq_length):
x = data[i:i+seq_length]
y = data[i+seq_length]
xs.append(x)
ys.append(y)
return np.array(xs), np.array(ys)
SEQ_LENGTH = 60 # utiliser 60 heures pour prédire la suivante
X, y = create_sequences(data_scaled, SEQ_LENGTH)
# Reshape pour Keras
X = X.reshape((X.shape[0], X.shape[1], 1))
# Définition du modèle GRU
model = Sequential([
GRU(64, return_sequences=False, input_shape=(SEQ_LENGTH, 1)),
Dense(1)
])
model.compile(optimizer=Adam(learning_rate=0.001), loss='mse')
# Entraînement
history = model.fit(
X, y, epochs=10, batch_size=128, validation_split=0.2, verbose=1
)
# Prédictions
predictions = model.predict(X)
predictions = scaler.inverse_transform(predictions)
data = scaler.inverse_transform(data_scaled)
# Visualisation des résultats
plt.figure(figsize=(12,6))
plt.plot(data, label="Données réelles")
plt.plot(
range(SEQ_LENGTH, len(predictions)+SEQ_LENGTH),
predictions, label="Prédictions GRU"
)
plt.legend()
#plt.show()
plt.savefig("Consommation.png")
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import GRU, Dense
from tensorflow.keras.optimizers import Adam
# Charger le dataset
df = pd.read_csv(
"household_power_consumption.csv", sep=';',
parse_dates={'datetime':['Date','Time']},
infer_datetime_format=True,
na_values='?',
low_memory=False
)
# Limiter à 100 000 lignes pour un test rapide
df = df.head(100000)
# Mettre datetime comme index
df = df.set_index('datetime')
# Agréger les mesures par heure
df = df.resample('H').mean().dropna()
# Garder uniquement Global_active_power
df = df[['Global_active_power']].dropna()
df['Global_active_power'] = df['Global_active_power'].astype(float)
# Normalisation
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(
df['Global_active_power'].values.reshape(-1,1)
)
# Création des séquences
def create_sequences(data, seq_length):
xs, ys = [], []
for i in range(len(data) - seq_length):
x = data[i:i+seq_length]
y = data[i+seq_length]
xs.append(x)
ys.append(y)
return np.array(xs), np.array(ys)
SEQ_LENGTH = 60 # utiliser 60 heures pour prédire la suivante
X, y = create_sequences(data_scaled, SEQ_LENGTH)
# Reshape pour Keras
X = X.reshape((X.shape[0], X.shape[1], 1))
# Définition du modèle GRU
model = Sequential([
GRU(64, return_sequences=False, input_shape=(SEQ_LENGTH, 1)),
Dense(1)
])
model.compile(optimizer=Adam(learning_rate=0.001), loss='mse')
# Entraînement
history = model.fit(
X, y, epochs=10, batch_size=128, validation_split=0.2, verbose=1
)
# Prédictions
predictions = model.predict(X)
predictions = scaler.inverse_transform(predictions)
data = scaler.inverse_transform(data_scaled)
# Visualisation des résultats
plt.figure(figsize=(12,6))
plt.plot(data, label="Données réelles")
plt.plot(
range(SEQ_LENGTH, len(predictions)+SEQ_LENGTH),
predictions, label="Prédictions GRU"
)
plt.legend()
#plt.show()
plt.savefig("Consommation.png")
Dans cet exemple, nous avons importé l'optimiseur Adam comme ceci:
from tensorflow.keras.optimizers import Adam
Cela permet de créer une instance explicite de l’optimiseur, par exemple Adam(learning_rate=0.001). Cela offre une flexibilité accrue en ajustant le taux d’apprentissage, les coefficients de régularisation ou d’autres hyperparamètres.
On charge le dataset:
df = pd.read_csv(
"household_power_consumption.csv", sep=';',
parse_dates={'datetime':['Date','Time']},
infer_datetime_format=True,
na_values='?',
low_memory=False
)
Le séparateur utilisé est ';' car les colonnes du fichier sont délimitées par des points-virgules. Les colonnes Date et Time sont fusionnées en une seule variable datetime, ce qui facilite l’analyse temporelle. L’option infer_datetime_format=True permet de reconnaître automatiquement le format des dates, tandis que na_values='?' indique que les valeurs manquantes sont représentées par le caractère ?. Enfin, low_memory=False garantit une lecture plus fiable du fichier volumineux en évitant des erreurs de typage lors du chargement.
"household_power_consumption.csv", sep=';',
parse_dates={'datetime':['Date','Time']},
infer_datetime_format=True,
na_values='?',
low_memory=False
)
Ensuite, on prépare un jeu de données de consommation électrique pour une analyse rapide:
# Limiter à 100 000 lignes pour un test rapide
df = df.head(100000)
# Mettre datetime comme index
df = df.set_index('datetime')
# Agréger les mesures par heure
df = df.resample('H').mean().dropna()
D’abord, on limite l’échantillon à 100 000 lignes afin de réduire le temps de calcul. Ensuite, la colonne datetime est définie comme index temporel, ce qui permet de manipuler les données par période. Enfin, les valeurs sont agrégées par heure grâce à la méthode resample('H').mean(), ce qui calcule la moyenne de consommation pour chaque heure et supprime les éventuelles valeurs manquantes avec dropna().
df = df.head(100000)
# Mettre datetime comme index
df = df.set_index('datetime')
# Agréger les mesures par heure
df = df.resample('H').mean().dropna()
Ensuite, on applique une normalisation Min-Max sur la colonne Global_active_power:
# Normalisation
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(
df['Global_active_power'].values.reshape(-1,1)
)
Ainsi, les valeurs en transformées en une échelle comprise entre 0 et 1 pour faciliter l’analyse et l’entraînement de modèles.
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(
df['Global_active_power'].values.reshape(-1,1)
)
Comme pour les exemples précédents, on crée les séquences adaptées aux modèles RNN en appliquant une fenêtre glissante:
# Création des séquences
def create_sequences(data, seq_length):
xs, ys = [], []
for i in range(len(data) - seq_length):
x = data[i:i+seq_length]
y = data[i+seq_length]
xs.append(x)
ys.append(y)
return np.array(xs), np.array(ys)
SEQ_LENGTH = 60 # utiliser 60 heures pour prédire la suivante
X, y = create_sequences(data_scaled, SEQ_LENGTH)
La fonction create_sequences génère des séquences temporelles de 60 heures consécutives de consommation normalisée pour prédire la valeur de l’heure suivante.
def create_sequences(data, seq_length):
xs, ys = [], []
for i in range(len(data) - seq_length):
x = data[i:i+seq_length]
y = data[i+seq_length]
xs.append(x)
ys.append(y)
return np.array(xs), np.array(ys)
SEQ_LENGTH = 60 # utiliser 60 heures pour prédire la suivante
X, y = create_sequences(data_scaled, SEQ_LENGTH)
La prochaine étape consiste à construire, compiler et entrainer notre modèle:
# Définition du modèle GRU
model = Sequential([
GRU(64, return_sequences=False, input_shape=(SEQ_LENGTH, 1)),
Dense(1)
])
model.compile(optimizer=Adam(learning_rate=0.001), loss='mse')
# Entraînement
history = model.fit(
X, y, epochs=10, batch_size=128, validation_split=0.2, verbose=1
)
Le modèle séquentiel construit repose sur une couche GRU de 64 unités suivie d’une couche dense, ce qui lui permet d’apprendre les dépendances temporelles sur 60 heures de données pour prédire la consommation électrique suivante. Ensuite, il est compilé avec l’optimiseur Adam et la fonction de perte MSE, puis entraîné sur 10 époques avec un batch de 128 et une validation de 20%, afin d’ajuster ses paramètres et améliorer la précision des prévisions.
model = Sequential([
GRU(64, return_sequences=False, input_shape=(SEQ_LENGTH, 1)),
Dense(1)
])
model.compile(optimizer=Adam(learning_rate=0.001), loss='mse')
# Entraînement
history = model.fit(
X, y, epochs=10, batch_size=128, validation_split=0.2, verbose=1
)
Enfin, on inverse la normalisation des données et des prédictions (après avoir calculé ces dernières) afin de retrouver les valeurs originales de consommation électrique, puis on trace un graphique comparant les données réelles et les prédictions du modèle GRU sur la même courbe temporelle:
# Prédictions
predictions = model.predict(X)
predictions = scaler.inverse_transform(predictions)
data = scaler.inverse_transform(data_scaled)
# Visualisation des résultats
plt.figure(figsize=(12,6))
plt.plot(data, label="Données réelles")
plt.plot(
range(SEQ_LENGTH, len(predictions)+SEQ_LENGTH),
predictions, label="Prédictions GRU"
)
plt.legend()
#plt.show()
plt.savefig("Consommation.png")
Ce qui produit cette illustration:
predictions = model.predict(X)
predictions = scaler.inverse_transform(predictions)
data = scaler.inverse_transform(data_scaled)
# Visualisation des résultats
plt.figure(figsize=(12,6))
plt.plot(data, label="Données réelles")
plt.plot(
range(SEQ_LENGTH, len(predictions)+SEQ_LENGTH),
predictions, label="Prédictions GRU"
)
plt.legend()
#plt.show()
plt.savefig("Consommation.png")
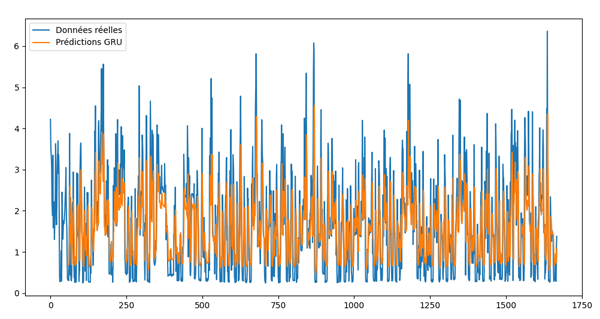
On note que la courbe des prédictions suit une tendance générale similaire aux données réelles, avec un alignement partiel. Toutefois, les résultats pourraient être améliorés en utilisant l’ensemble complet du jeu de données pour l’entraînement, ce qui permettrait au modèle de mieux capturer les variations et les comportements de la consommation électrique.
Leçon 17
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Leçon 21
Analyse des séries temporelles de consommation électrique domestique par réseaux GRU
Analyse des séries temporelles de consommation électrique domestique par réseaux GRU


