Deep Learning: comprendre et construire des réseaux de neurones






Leçon 1: Deep Learning et réseaux de neurones: définition, utilité et histoire d'évolution
Toutes les leçons 
Deep Learning: comprendre et construire des réseaux de neurones
Leçon 1
Deep Learning et réseaux de neurones: définition, utilité et histoire d'évolution
Deep Learning et réseaux de neurones: définition, utilité et histoire d'évolution
L’utilité du Deep Learning: pourquoi aller au-delà du Machine Learning ?
Qu'est ce que le Deep Learning?
Le Deep Learning (ou apprentissage profond) est une branche de l’intelligence artificielle qui s’appuie sur des réseaux de neurones artificiels composés de nombreuses couches. Chaque couche transforme les données brutes en représentations plus abstraites, permettant au système de découvrir automatiquement des motifs complexes. Cette hiérarchie de traitement rend le Deep Learning particulièrement performant pour des tâches comme la reconnaissance d’images, l’analyse de la voix ou la compréhension du langage naturel.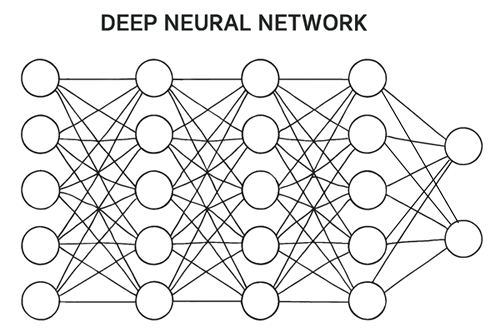
Contrairement aux approches plus classiques, le deep learning ne nécessite pas que l’humain définisse manuellement les caractéristiques pertinentes. En effet, les réseaux eux-mêmes apprennent à les extraire à partir de grandes quantités de données. Cette capacité d’auto-apprentissage, couplée à la puissance des processeurs modernes et à l’explosion des données disponibles, explique pourquoi le Deep Learning est devenu un pilier incontournable de l’IA contemporaine.
Deep Learning vs Machine Learning: comprendre l'apport
Contrairement au Machine Learning traditionnel, qui repose souvent sur des étapes manuelles de feature engineering, le Deep Learning automatise ce processus grâce à ses réseaux de neurones profonds. Par exemple, dans la reconnaissance d’images, un algorithme de Machine Learning classique nécessitait que l’on définisse manuellement des caractéristiques comme les contours, les couleurs ou les formes. Avec un réseau convolutif (CNN), le Deep Learning apprend lui-même à détecter ces motifs, puis à les combiner pour reconnaître un visage ou un objet. De même, dans le traitement du langage naturel (ou NLP), les modèles traditionnels utilisaient des représentations simplifiées comme les sacs de mots (bag of words), tandis que les architectures modernes (LSTM, Transformers) capturent automatiquement le sens et le contexte des phrases, ce qui a permis des avancées majeures en traduction automatique et en assistants virtuels. Enfin, dans les véhicules autonomes, le Deep Learning intègre simultanément des flux de données visuelles, sonores et contextuelles pour prendre des décisions en temps réel, là où le Machine Learning classique aurait eu du mal à gérer cette complexité.En résumé, le Deep Learning offre une scalabilité et une performance supérieures, ouvrant la voie à des applications que le Machine Learning traditionnel ne pouvait pas atteindre avec la même précision ni la même autonomie.
Même si le Deep Learning est reconnu pour ses performances supérieures, il n’est pas toujours la solution idéale. Dans certains contextes, on préfère recourir au Machine Learning classique pour sa simplicité de mise en œuvre et surtout pour son interprétabilité. Par exemple, un modèle de régression logistique ou un arbre de décision permet de comprendre facilement pourquoi une prédiction a été faite, ce qui est crucial dans des domaines sensibles comme la santé ou la finance. Le Deep Learning, en revanche, est souvent perçu comme une "boîte noire", plus difficile à expliquer aux décideurs ou aux régulateurs.
Histoire d'évoluation du Deep Learning
Les réseaux ce neurones: origines
L’histoire du Deep Learning remonte aux années 1950 avec la création du Perceptron par Frank Rosenblatt, considéré comme le premier modèle de neurone artificiel. Dans les décennies suivantes, les chercheurs ont exploré différentes architectures, mais les limites technologiques (puissance de calcul insuffisante et manque de données massives) ont freiné les avancées. Les années 1980 ont marqué un tournant avec l’introduction de la rétropropagation (backpropagation), qui a permis d’entraîner efficacement des réseaux multicouches. Cependant, malgré cet apport, le Deep Learning est resté en retrait pendant longtemps, éclipsé par d’autres approches plus simples du Machine Learning.Les ingrédients magiques du Deep Learning: GPU et données massives
À partir des années 2000, l’essor du Deep Learning a été rendu possible grâce à l’utilisation des GPU (Graphics Processing Units). Initialement conçus pour le rendu graphique dans les jeux vidéo, ces processeurs se sont révélés extrêmement efficaces pour exécuter en parallèle les milliers d’opérations nécessaires à l’entraînement des réseaux de neurones. Là où les CPU classiques traitent les calculs de manière séquentielle, les GPU permettent de multiplier les opérations en parallèle, réduisant considérablement le temps d’apprentissage des modèles. Cette puissance de calcul a ouvert la voie à des architectures plus profondes et plus complexes, capables de traiter des volumes de données auparavant inaccessibles.En parallèle, l’explosion des datasets massifs a constitué l’autre ingrédient magique du Deep Learning. Des bases de données comme ImageNet, contenant des millions d’images annotées, ont permis d’entraîner des modèles capables de reconnaître des objets avec une précision inédite. En 2012, le réseau AlexNet a marqué un tournant historique en surpassant largement les méthodes traditionnelles lors du concours ImageNet, grâce à la combinaison de GPU puissants et de données abondantes. Depuis, les architectures se sont diversifiées: CNN pour la vision, RNN/LSTM pour les séquences, et plus récemment les Transformers qui dominent le traitement du langage naturel (par exemple BERT et GPT).
Aujourd’hui, le Deep Learning est au cœur des applications modernes de l’IA, allant des assistants vocaux aux véhicules autonomes, et continue d’évoluer grâce à la synergie entre puissance de calcul et disponibilité des données.
Les prérequis essentiels: programmation, Machine Learning et curiosité
Pour aborder ce cours de Deep Learning, il est utile d’avoir quelques notions en mathématiques (algèbre linéaire, probabilités, calcul différentiel) et en programmation, notamment avec Python et ses bibliothèques scientifiques. Ces bases facilitent la compréhension des mécanismes internes des réseaux de neurones.Toutefois, il est important de préciser que l’on peut s’en sortir même sans un bagage mathématique avancé. En effet, de nombreux outils, frameworks (comme TensorFlow ou PyTorch) et ressources pédagogiques permettent de manipuler et expérimenter directement les modèles. L’essentiel est d’avoir une curiosité active, une bonne maîtrise des concepts fondamentaux du Machine Learning (classification, régression...) et une volonté de pratiquer sur des exemples concrets.
Leçon 1
Deep Learning et réseaux de neurones: définition, utilité et histoire d'évolution
Deep Learning et réseaux de neurones: définition, utilité et histoire d'évolution

