Deep Learning: comprendre et construire des réseaux de neurones






Leçon 7: Training Loss et Validation Loss: détecter l'overfitting dans les réseaux de neurones
Toutes les leçons 
Deep Learning: comprendre et construire des réseaux de neurones
Leçon 7
Training Loss et Validation Loss: détecter l'overfitting dans les réseaux de neurones
Training Loss et Validation Loss: détecter l'overfitting dans les réseaux de neurones
Surveiller l'overfitting grâce à la validation loss
Learning Curve: visualiser la progression de l’apprentissage
La courbe d’apprentissage (Learning Curve) constitue un outil central pour analyser le comportement d’un réseau de neurones au fil des époques. Elle illustre l’évolution de la perte (loss) en fonction du nombre d’itérations, permettant de visualiser comment le modèle réduit progressivement ses erreurs. Cette représentation met en évidence la dynamique d’apprentissage et offre une lecture claire de la convergence du réseau vers une solution plus optimale tout en facilitant la détection d’éventuels problèmes comme le surapprentissage.Une courbe qui descend régulièrement traduit un apprentissage efficace, tandis qu’une stagnation ou une remontée peut signaler un problème de sous-apprentissage (underfitting) ou de surapprentissage (overfitting).
Les phénomènes d’underfitting et d’overfitting ne concernent pas uniquement les réseaux de neurones, mais touchent aussi les modèles classiques comme la régression ou les arbres de décision. Cependant, ils sont particulièrement critiques en deep learning, car la complexité et le grand nombre de paramètres des réseaux profonds accentuent ces risques. D’où l’importance de surveiller attentivement les métriques de validation pour garantir une bonne généralisation.
Lorsque l’on ajoute une courbe de validation en parallèle, il devient possible de comparer la performance sur les données d’entraînement et sur des données inédites, ce qui aide à ajuster le nombre d’époques et à prévenir l’overfitting.
Si on veut visualiser la learning curve du modèle de la séance précédente, on remplace tout simplement l'instruction d'entrainement par ceci:
# Entrainement
history=model.fit(
X_scaled,y_scaled,epochs=300, validation_split=0.2
)
Dans l’objet history retourné par Keras après l’entraînement, la clé history.history["loss"] correspond à l’évolution de la perte sur l’ensemble d’entraînement au fil des époques. Elle indique dans quelle mesure le modèle parvient à s’adapter aux données qu’il utilise pour ajuster ses poids.
history=model.fit(
X_scaled,y_scaled,epochs=300, validation_split=0.2
)
En parallèle, history.history["val_loss"] enregistre la perte sur l’ensemble de validation, c’est‑à‑dire sur des données mises de côté et non utilisées pour l’apprentissage direct.
D'ailleurs, lors de l'entrainement, Keras affiche un rapport à chaque époque. Ce rapport ne se limite pas à la valeur de la training loss, mais inclut également la validation loss, ainsi que d’autres métriques définies lors de la compilation du modèle, comme l’erreur absolue moyenne (mae) ou l’erreur quadratique moyenne (mse) et leurs équivalents sur l’ensemble de validation (val_mae, val_mse).
Epoch 32/300
3/3 ━━━━━━ 0s 95ms/step - loss: 0.0542 - mae: 0.1794 - mse: 0.0542 - val_loss: 0.3143 - val_mae: 0.5281 - val_mse: 0.3143
L’affichage permet donc de suivre simultanément la progression du réseau de neurones sur les données d’apprentissage et sur les données de validation, offrant une vision complète de la performance et facilitant la détection d’un éventuel surapprentissage.
3/3 ━━━━━━ 0s 95ms/step - loss: 0.0542 - mae: 0.1794 - mse: 0.0542 - val_loss: 0.3143 - val_mae: 0.5281 - val_mse: 0.3143
Surveiller la performance réelle et l’overfitting grâce à la validation loss
La validation loss est un indicateur fondamental pour mesurer la capacité d’un modèle à généraliser au-delà des données utilisées pendant l’entraînement.Lorsqu’un réseau est entraîné avec l’option validation_split=0.2, Keras réserve automatiquement 20% des données pour constituer un ensemble de validation. Cet ensemble n’intervient pas dans l’optimisation des poids, mais sert uniquement à évaluer la performance du modèle sur des exemples qu’il n’a jamais vus.
La perte calculée sur ce set de validation (val_loss) permet ainsi de comparer la progression de l’apprentissage avec la réalité de la généralisation. Contrairement à la training loss, qui reflète uniquement l’adaptation du modèle aux données d’entraînement, la validation loss révèle les signes de surapprentissage (overfitting). En effet, une baisse continue de la training loss accompagnée d’une hausse de la validation loss indique que le modèle mémorise trop les données d’entraînement et perd en robustesse.
En pratique, suivre la validation loss est indispensable pour ajuster le nombre d’époques, l’architecture ou les hyperparamètres afin d’obtenir un modèle fiable et performant sur de nouvelles données.
Pour visualiser la learning curve (y compris la validation loss), on peut exécuter ce code:
# Entrainement
history=model.fit(X_scaled,y_scaled,epochs=300, validation_split=0.2)
# Learning Curve
plt.plot(history.history["loss"], label="Training Loss")
plt.plot(history.history["val_loss"], label="Validation Loss")
plt.xlabel("Époques")
plt.ylabel("Loss")
plt.title("Courbe d'apprentissage")
plt.legend()
plt.show()
history=model.fit(X_scaled,y_scaled,epochs=300, validation_split=0.2)
# Learning Curve
plt.plot(history.history["loss"], label="Training Loss")
plt.plot(history.history["val_loss"], label="Validation Loss")
plt.xlabel("Époques")
plt.ylabel("Loss")
plt.title("Courbe d'apprentissage")
plt.legend()
plt.show()
Le code précédent produit ce résultat:
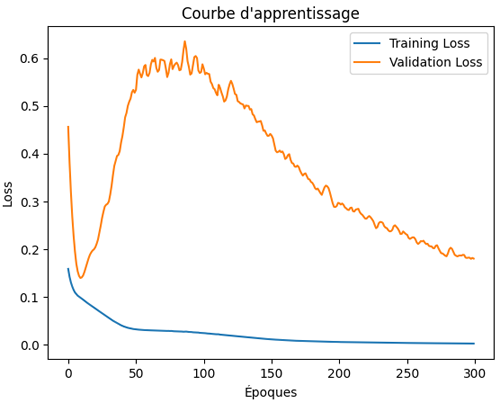
On constate que training loss diminue progressivement au fil des époques, cela traduit une amélioration constante de l’adaptation du réseau de neurones aux données d’entraînement. En effet, le modèle apprend à réduire ses erreurs internes.
En revanche, on constate une validation loss instable au début (elle descend puis remonte avant de redescendre progressivement), ce qui constitue un comportement assez fréquent. Cette phase traduit l’ajustement initial du modèle, où les poids s’adaptent rapidement et peuvent provoquer des fluctuations sur l’ensemble de validation. Le fait qu’elle se stabilise et baisse ensuite indique que le réseau parvient à mieux généraliser, réduisant ses erreurs sur des données qu’il n’a pas vues.
En somme, cette dynamique suggère un apprentissage sain, c'est à dire que le modèle apprend efficacement sans tomber dans un surapprentissage marqué.
Leçon 7
Training Loss et Validation Loss: détecter l'overfitting dans les réseaux de neurones
Training Loss et Validation Loss: détecter l'overfitting dans les réseaux de neurones
 Quiz
Quiz 

