Deep Learning: comprendre et construire des réseaux de neurones






Leçon 8: Réseaux de neurones appliqués à la classification binaire
Toutes les leçons 
Deep Learning: comprendre et construire des réseaux de neurones
Leçon 8
Réseaux de neurones appliqués à la classification binaire
Réseaux de neurones appliqués à la classification binaire
Classification binaire pour la prédiction de survie au bord du Titanic
Prédiction de survie au bord du Titanic à l'aide d'un réseau de neurones
Dans le cadre de cet exemple, nous allons procéder à la prédiction de la survie des passagers du Titanic en formulant le problème comme une classification binaire.Chaque individu est associé à une étiquette (1 s’il a survécu, 0 sinon). Pour ce faire, nous mobiliserons un réseau de neurones artificiels construit avec Keras/TensorFlow. Ce modèle, composé de plusieurs couches denses et activations non linéaires, sera entraîné sur les caractéristiques disponibles (âge, sexe, classe, etc.) afin d’apprendre à distinguer les profils de passagers susceptibles de survivre.
L’utilisation d’une couche de sortie sigmoïde permettra de générer une probabilité de survie comprise entre 0 et 1, que nous transformerons ensuite en prédiction binaire.
Je rappelle que nous avons déjà traité le dataset Titanic à plusieurs reprises dans les cours de Machine Learning et de Feature Engineering.
Architecture complète du réseau de neurones appliqué à la classification binaire
Encore une fois, je vais vous montrer le code complet en une seule fois, puis je m'arrêterai sur les partie qu inécessitent des exiplications détaillées.import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
from tensorflow.keras.metrics import Precision, Recall
df = pd.read_csv("titanic.csv")
df = df[["Survived",
"Pclass",
"Sex",
"Age",
"SibSp",
"Parch",
"Fare"]].dropna()
df["Sex"] = df["Sex"].map({"male": 0, "female": 1})
X = df.drop("Survived", axis=1)
y = df["Survived"]
model=Sequential([
Input(shape=(X.shape[1],)),
Dense(50,activation="relu"),
Dense(50,activation="relu"),
Dense(1,activation="sigmoid")
])
model.compile(
loss="binary_crossentropy",optimizer="adam",
metrics=["accuracy", Precision(), Recall()]
)
model.summary()
X_train,X_test,y_train,y_test=train_test_split(
X,y,test_size=0.2,random_state=42
)
history=model.fit(
X_train,y_train,epochs=200, validation_split=0.2
)
model.evaluate(X_test,y_test)
y_pred_proba=model.predict(X_test)
y_pred = (y_pred_proba > 0.5).astype("int32")
print(classification_report(y_test,y_pred))
print(confusion_matrix(y_test,y_pred))
plt.plot(history.history["loss"], label="Training Loss")
plt.plot(history.history["val_loss"], label="Validation Loss")
plt.xlabel("Époques")
plt.ylabel("Loss")
plt.title("Courbe d'apprentissage")
plt.legend()
plt.show()
Comme pour chaque projet, on commence par importer les modules nécessaires. Cette fois, nous allons faire les choses proprement et nous procéderons à la séparation des données de l'entrainement des données de test à l'aide du module train_test_split.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
from tensorflow.keras.metrics import Precision, Recall
df = pd.read_csv("titanic.csv")
df = df[["Survived",
"Pclass",
"Sex",
"Age",
"SibSp",
"Parch",
"Fare"]].dropna()
df["Sex"] = df["Sex"].map({"male": 0, "female": 1})
X = df.drop("Survived", axis=1)
y = df["Survived"]
model=Sequential([
Input(shape=(X.shape[1],)),
Dense(50,activation="relu"),
Dense(50,activation="relu"),
Dense(1,activation="sigmoid")
])
model.compile(
loss="binary_crossentropy",optimizer="adam",
metrics=["accuracy", Precision(), Recall()]
)
model.summary()
X_train,X_test,y_train,y_test=train_test_split(
X,y,test_size=0.2,random_state=42
)
history=model.fit(
X_train,y_train,epochs=200, validation_split=0.2
)
model.evaluate(X_test,y_test)
y_pred_proba=model.predict(X_test)
y_pred = (y_pred_proba > 0.5).astype("int32")
print(classification_report(y_test,y_pred))
print(confusion_matrix(y_test,y_pred))
plt.plot(history.history["loss"], label="Training Loss")
plt.plot(history.history["val_loss"], label="Validation Loss")
plt.xlabel("Époques")
plt.ylabel("Loss")
plt.title("Courbe d'apprentissage")
plt.legend()
plt.show()
Vous avez certainement remarqué l'importation des métriques precision et recall:
from tensorflow.keras.metrics import Precision, Recall
Dans Keras, il n’est pas recommandé d’indiquer directement "precision" et "recall" comme chaînes de caractères dans la fonction compile car ces noms ne correspondent pas à des métriques intégrées par défaut. En effet, Keras ne reconnaît que certaines métriques standards (comme "accuracy"), tandis que la précision et le rappel doivent être importés explicitement sous forme de classes (Precision() et Recall()) depuis tensorflow.keras.metrics.
Concernant la construction du modèle, il y a un tout petit changement par rapport à l'exemple de la leçon précédente:
model=Sequential([
Input(shape=(X.shape[1],)),
Dense(50,activation="relu"),
Dense(50,activation="relu"),
Dense(1,activation="sigmoid")
])
En effet, nous avons utilisé la fonction d'activation sigmoid pour la couche de sortie afin d'implémenter une classification binaire (sous forme de probabilité comprise entre 0 et 1). Lors de la dernire leçon, nous n'avons appliqué aucune fonction d'activation à cette couchce car il il s'agissait d'un problème de régression.
Input(shape=(X.shape[1],)),
Dense(50,activation="relu"),
Dense(50,activation="relu"),
Dense(1,activation="sigmoid")
])
Dans la couche d'entrée, au lieux d'expliciter directement le nombre de feature 6, nous l'avons renseigné dynamiquement à l'aide de X.shape[1].
L'étape suivante consiste à configurer le réseau de neurones pour une classification binaire:
model.compile(
loss="binary_crossentropy",optimizer="adam",
metrics=["accuracy", Precision(), Recall()]
)
La fonction de perte binary_crossentropy mesure l’écart entre les probabilités prédites et les vraies étiquettes (0 ou 1), l’optimiseur adam ajuste efficacement les poids du modèle. Quant aux métriques accuracy, Precision() et Recall(), elles permettent de suivre respectivement la proportion de prédictions correctes, la précision des prédictions positives et la capacité du modèle à détecter les vrais positifs.
loss="binary_crossentropy",optimizer="adam",
metrics=["accuracy", Precision(), Recall()]
)
Dans cet exemple, nous avons procédé à la séparation les données d'entrainement et du test conformément aux bonnes pratiques en data science:
X_train,X_test,y_train,y_test=train_test_split(
X,y,test_size=0.2,random_state=42
)
Vient ensuite la phase d'entrainement de notre modèle:
X,y,test_size=0.2,random_state=42
)
history=model.fit(X_train,y_train,epochs=200, validation_split=0.2)
Le modèle est entraîné sur les données X_train et y_train pendant 200 époques. L’argument validation_split=0.2 indique que 20% des données d’entraînement seront automatiquement réservées pour l’évaluation interne du modèle à chaque époque. La variable history stocke ensuite toutes les informations de l’entraînement (valeurs de la loss et des métriques par époque), ce qui permet de tracer les courbes d’apprentissage et d’analyser la progression du modèle.
Voilà un extrait du rapport d'entrainement concernant la première époque:
Epoch 1/200
15/15 ━━━━━━ 6s 110ms/step - accuracy: 0.6864 - loss: 0.6570 - precision_1: 0.6560 - recall_1: 0.4505 - val_accuracy: 0.6783 - val_loss: 0.7224 - val_precision_1: 0.7778 - val_recall_1: 0.4038
Une étape essentielle consiste à transformer les probabilités produites par le modèle en prédictions binaires exploitables:
15/15 ━━━━━━ 6s 110ms/step - accuracy: 0.6864 - loss: 0.6570 - precision_1: 0.6560 - recall_1: 0.4505 - val_accuracy: 0.6783 - val_loss: 0.7224 - val_precision_1: 0.7778 - val_recall_1: 0.4038
y_pred_proba=model.predict(X_test)
y_pred = (y_pred_proba > 0.5).astype("int32")
La commande model.predict(X_test) génère pour chaque exemple du jeu de test une probabilité de survie (issue de la fonction sigmoïde). Ensuite, l’expression (y_pred_proba > 0.5).astype("int32") applique un seuil de décision, autement dit, si la probabilité est supérieure à 0.5, l’étiquette est fixée à 1 (survie), sinon à 0 (non‑survie).
y_pred = (y_pred_proba > 0.5).astype("int32")
L’utilité de cette étape est donc de convertir les sorties continues du réseau en classes discrètes, ce qui permet d’évaluer le modèle avec des métriques de classification comme l’accuracy, la précision ou le rappel.
La suite des instructions représente la phase classique de tout projet de classification comprenant l’évaluation du modèle, la génération d’un rapport de classification et la production de supports visuels complémentaires tels que la matrice de confusion.
A titre d'exemple, voilà à quoi ressemble la matrice de confusion dans notre cas:
[[ 67 20 ]
[ 16 40 ]]
[ 16 40 ]]
Il est important de préciser que l’objectif de cette section n’est pas d’évaluer en détail les performances du modèle puisque ce type d’opération a déjà été réalisé à plusieurs reprises. Notre intérêt se porte plutôt sur l’observation du comportement du réseau de neurones pendant son entraînement afin de mieux comprendre la dynamique des courbes de perte et de validation, ainsi que les tendances générales qui traduisent la capacité du modèle à apprendre et à généraliser.
Visualisons la courbe d’apprentissage (Learning Curve) de notre modèle:
plt.plot(history.history["loss"], label="Training Loss")
plt.plot(history.history["val_loss"], label="Validation Loss")
plt.xlabel("Époques")
plt.ylabel("Loss")
plt.title("Courbe d'apprentissage")
plt.legend()
plt.show()
L'exécution de ces instrcutions produit ce graphique:
plt.plot(history.history["val_loss"], label="Validation Loss")
plt.xlabel("Époques")
plt.ylabel("Loss")
plt.title("Courbe d'apprentissage")
plt.legend()
plt.show()
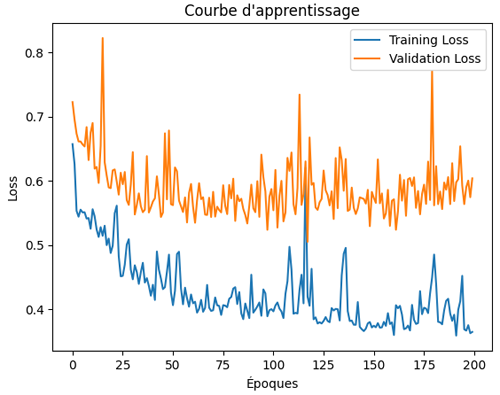
La courbe d’apprentissage montre que le modèle apprend bien sur les données d’entraînement puisque la loss générale diminue malgré les oscillations (zigzag liés au bruit ou à la taille des batchs). En revanche, la val_loss baisse au début, ce qui indique une bonne généralisation initiale, puis elle se stabilise et remonte légèrement vers la fin. Ce comportement traduit un début d’overfitting: le réseau continue à s’améliorer sur l’entraînement mais perd en capacité de généralisation sur les données de validation.
Plus loin dans ce cours, nous explorerons en détail les techniques permettant de minimiser l’overfitting, telles que l’early stopping, la régularisation (L1/L2, dropout) ou encore l’augmentation des données. Ces approches seront présentées comme des outils essentiels pour améliorer la capacité de généralisation des réseaux de neurones et renforcer la robustesse des modèles de classification.
Leçon 8
Réseaux de neurones appliqués à la classification binaire
Réseaux de neurones appliqués à la classification binaire


