Deep Learning: comprendre et construire des réseaux de neurones






Leçon 10: Prévenir l'overfitting grace à la régularisation: principes et techniques fondamentales
Toutes les leçons 
Deep Learning: comprendre et construire des réseaux de neurones
Leçon 10
Prévenir l'overfitting grace à la régularisation: principes et techniques fondamentales
Prévenir l'overfitting grace à la régularisation: principes et techniques fondamentales
Régularisation: Comment éviter que le réseau devienne prisonnier des données d’entraînement?
Pourquoi la régularisation?
Lorsqu’un réseau de neurones est entraîné, il cherche naturellement à minimiser l’erreur sur les données d’apprentissage. Mais s’il dispose de trop de paramètres ou s’il est entraîné trop longtemps, il risque de mémoriser les exemples au lieu d’apprendre les tendances générales. Ce phénomène, appelé surapprentissage (ou overfitting), conduit à des performances excellentes sur le jeu d’entraînement mais médiocres sur des données nouvelles (y compris les données de test).La régularisation intervient comme une stratégie de contrôle. En effet, elle impose des contraintes ou introduit de la variabilité pour empêcher le modèle de devenir trop complexe. En d’autres termes, elle agit comme une forme de "discipline" qui oblige le réseau à rester sobre, à se concentrer sur les caractéristiques essentielles et à ignorer le bruit ou les détails superflus.
Grâce à la technique de régularisation, le modèle devient plus robuste, plus simple et plus apte à généraliser dans des contextes variés.
En pratique, la régularisation repose sur plusieurs approches complémentaires : les pénalités sur les poids (L1 et L2) qui limitent la complexité des paramètres, le Dropout qui réduit la co‑adaptation des neurones, l’Early Stopping qui interrompt l’entraînement avant le surapprentissage, la Batch Normalization qui stabilise les activations, ainsi que l’augmentation des données qui enrichit artificiellement le jeu d’apprentissage pour améliorer la robustesse du modèle.
Il existe d’autres mécanismes de régularisation tels que l’injection de bruit, le weight sharing, le pruning ou encore les techniques de distillation de modèles. Toutefois, dans ce cours, nous allons nous concentrer sur les méthodes les plus courantes et les plus utilisées en pratique afin de poser des bases solides avant d’aborder des approches plus avancées.
Méthodes de régularisation des réseaux de neurones
Régularisation L1 (Lasso)
La régularisation L1, connue souvent soue le nom de Lasso (pour Least Absolute Shrinkage and Selection Operator), consiste à ajouter une pénalité proportionnelle à la valeur absolue des poids dans la fonction de coût. Mathématiquement, on ajoute un terme:\(\lambda \sum |w_i|\)
où \(\lambda\) est un hyperparamètre qui contrôle l’importance de la régularisation.
Son effet principal est de favoriser la parsité. Autrement dit, beaucoup de poids deviennent exactement nuls, ce qui conduit le réseau à sélectionner uniquement les caractéristiques les plus pertinentes.
En pratique, la régularisation L1 agit comme un mécanisme de sélection de variables, réduisant la complexité du modèle et rendant l’interprétation plus facile.
Régularisation L2 (Ridge)
La régularisation L2, aussi appelée ridge regression ou weight decay, ajoute une pénalité proportionnelle au carré des poids dans la fonction de coût. Le terme ajouté est:\(\lambda \sum w_i^2\)
Contrairement à L1, L2 ne force pas les poids à devenir nuls, mais les contraint à rester petits et homogènes. Cela empêche certains paramètres de dominer l’apprentissage et stabilise le modèle. La régularisation L2 est particulièrement efficace pour améliorer la robustesse et réduire la variance, tout en conservant l’ensemble des caractéristiques.
Technique du Dropout
Le Dropout est une technique de régularisation très utilisée en deep learning. Son principe repose sur la désactivation aléatoire d'un certain pourcentage de neurones dans le réseau pendant l'entrainement. Cela signifie que, pour chaque itération, le modèle apprend avec une architecture légèrement différente.L'approche du Dropout empêche les neurones de s'adapter trop fortement entre eux, ce qui réduit le risque de surapprentissage.
En pratique, Dropout agit comme une forme d’ensemble learning implicite. En effet, au lieu d’entraîner un seul réseau, on entraîne simultanément une multitude de sous‑réseaux, et leur combinaison rend le modèle final plus robuste.
Lors de l’inférence (prédiction), tous les neurones sont réactivés, mais leurs poids sont ajustés pour compenser la phase d’entraînement.
Dropout est particulièrement efficace dans les réseaux profonds (ANN, CNN et RNN) et reste une des techniques de régularisation les plus populaires grâce à sa simplicité et son efficacité.
Batch Normalization
La Batch Normalization (BN) est une technique introduite pour améliorer la stabilité et la rapidité de l’entraînement des réseaux de neurones profonds. Son principe est de normaliser les activations d’une couche en les ramenant à une distribution centrée et réduite (moyenne proche de zéro et variance proche de un) pour chaque mini‑lot (batch) de données.Concrètement, la technique de la Batch Normalization réduit le problème du covariate shift interne, c’est‑à‑dire les variations trop importantes dans la distribution des activations au fil des couches. En stabilisant ces activations, l’optimisation devient plus efficace, ce qui mène le réseau à converger plus rapidement et peut utiliser des taux d’apprentissage plus élevés.
Un autre effet important est que Batch Normalization agit comme une forme implicite de régularisation. En introduisant une petite quantité de bruit statistique lors de la normalisation, elle réduit le risque de surapprentissage et améliore la généralisation. C’est pourquoi Batch Normalization est aujourd’hui largement utilisée dans les architectures modernes, notamment les CNN et les réseaux très profonds.
Early Stopping
L’Early Stopping est une technique de régularisation simple mais très efficace. Elle repose sur l’idée que le surapprentissage apparaît généralement après un certain nombre d’itérations: le modèle continue à améliorer ses performances sur le jeu d’entraînement, mais sa performance sur le jeu de validation commence à se dégrader comme on l'a vu à travers la learning curve liée à la classification binaire traitée dans ce cours: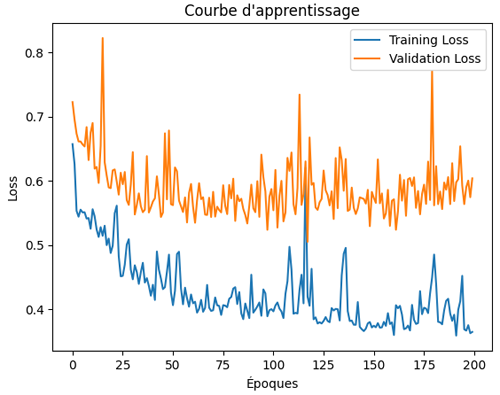
Le principe est donc de surveiller l’erreur de validation pendant l’entraînement et d’arrêter le processus dès que cette erreur cesse de diminuer. Cela permet de conserver le modèle au moment où il est le plus capable de généraliser sans qu’il ait eu le temps de mémoriser excessivement les données d’entraînement.
En pratique, l’early stopping est souvent combiné avec d’autres techniques comme la régularisation L2 ou le Dropout. Il est particulièrement apprécié car il ne nécessite aucune modification de l’architecture du réseau. En effet, il suffit de définir un critère d’arrêt basé sur la performance de validation.
Data Augmentation
La Data Augmentation est une technique de régularisation particulièrement utilisée dans le traitement d’images. Elle consiste à enrichir artificiellement le jeu de données d’entraînement en créant de nouvelles variantes des exemples existants. L’idée est de transformer les images de manière réaliste (rotations, translations, recadrages, inversions, changements de luminosité, ajout de bruit, etc.) afin que le réseau apprenne à reconnaître les caractéristiques essentielles indépendamment de ces variations.Cette approche permet de réduire le surapprentissage en exposant le modèle à une plus grande diversité de situations, sans avoir besoin de collecter de nouvelles données coûteuses.
En pratique, la data augmentation agit comme une forme de régularisation implicite: elle force le réseau à généraliser au‑delà des exemples strictement présents dans le jeu d’entraînement. C’est une technique incontournable dans les CNN appliqués à la vision par ordinateur, mais elle peut aussi être adaptée à d’autres domaines (texte, audio) avec des transformations spécifiques.
Je vous invite à consulter la leçon dédiée à la Data Augmentation et à l’Oversampling, que j’ai traitée dans mon cours de Feature Engineering. Vous y trouverez des explications plus détaillées et des exemples pratiques qui complètent cette introduction.
Leçon 10
Prévenir l'overfitting grace à la régularisation: principes et techniques fondamentales
Prévenir l'overfitting grace à la régularisation: principes et techniques fondamentales


