Deep Learning: comprendre et construire des réseaux de neurones






Leçon 22: Le mécanisme d'attention et la résolution des limites des RNN
Toutes les leçons 
Deep Learning: comprendre et construire des réseaux de neurones
Leçon 17
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Leçon 22
Le mécanisme d'attention et la résolution des limites des RNN
Le mécanisme d'attention et la résolution des limites des RNN
Le mécanisme d’attention: voir au-delà de la séquence
Les limites des RNN et la quête d’efficacité
Les réseaux récurrents (RNN), ainsi que leurs variantes LSTM et GRU, ont longtemps constitué la référence pour le traitement des séquences. Leur capacité à mémoriser des dépendances temporelles courtes a permis des avancées notables en traduction automatique ou en reconnaissance vocale. Cependant, ces architectures souffrent de plusieurs faiblesses qui ont progressivement révélé leurs limites :- Dépendances longues difficiles à capturer: plus une séquence est longue, plus le modèle peine à conserver une mémoire fiable des premiers éléments. Les RNN ont tendance à “oublier” les informations éloignées.
- Calcul séquentiel non parallélisable: chaque étape dépend de la précédente, ce qui ralentit considérablement l’entraînement et rend l’optimisation coûteuse sur de grands corpus.
- Problèmes de gradients: les RNN sont sujets au phénomène de vanishing gradients (les poids cessent d’évoluer) ou d’exploding gradients (les poids deviennent instables), ce qui complique l’apprentissage sur des séquences longues.
- Coût computationnel élevé: même avec des variantes comme LSTM ou GRU, l’entraînement reste lourd et peu adapté aux très grands ensembles de données modernes.
- Difficulté d’adaptation aux contextes complexes: les RNN traitent les séquences pas à pas, ce qui limite leur capacité à établir des relations globales entre des éléments distants d’une phrase ou d’un document.
Ces limites ont ouvert la voie à une réflexion sur des modèles capables de traiter les séquences de manière plus efficace, plus scalable et mieux adaptés aux besoins du NLP moderne.
Bien que les variantes des RNN comme les LSTM et les GRU aient été conçues pour atténuer certains problèmes des réseaux récurrents classiques (notamment le vanishing gradient et la difficulté à mémoriser des dépendances longues), ces limitations ne disparaissent pas totalement.
L’émergence du mécanisme d’attention
Le mécanisme d’attention repose sur une idée simple mais puissante: au lieu de traiter chaque élément de la séquence dans l’ordre, le modèle peut attribuer un poids d’importance à chaque mot ou symbole en fonction du contexte. Ainsi, il devient possible de mettre en avant les parties réellement pertinentes d’une phrase ou d’un document, indépendamment de leur position. Ce fonctionnement permet au modèle de construire une représentation plus riche et plus flexible, en capturant directement les relations entre les éléments distants.Concrètement, l’attention calcule une matrice de poids qui indique à quel point chaque mot "regarde" les autres. Ces poids sont ensuite utilisés pour produire une représentation contextuelle plus riche où chaque mot intègre l’information pertinente provenant de l’ensemble de la séquence.
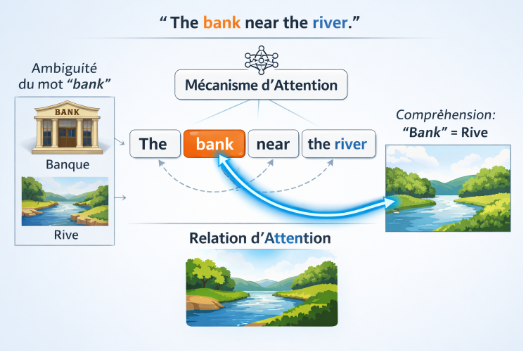
Prenons la phrase "The bank near the river". Le mot "bank" peut signifier "banque" ou "rive". Dans un RNN classique, l’interprétation dépendrait fortement de la mémoire séquentielle, qui pourrait perdre le lien avec le mot "river". Avec l’attention, le modèle calcule directement la relation entre "bank" et "river", et comprend que dans ce contexte que "bank" désigne la rive. Ce mécanisme permet donc de lever l’ambiguïté en reliant les mots pertinents, sans dépendre d’un chemin séquentiel fragile.
Le mécanisme d’attention a été formalisé dans l’article fondateur "Attention Is All You Need" (Vaswani et al., 2017), qui a introduit le concept de self-attention et posé les bases du modèle Transformer. Cet article marque un tournant majeur dans le Deep Learning en montrant qu’il est possible de se passer totalement des réseaux récurrents pour modéliser des séquences.
Vers une nouvelle génération de modèles de Deep Learning
L’introduction du mécanisme d’attention a constitué une véritable rupture dans l’histoire du Deep Learning. Jusque-là, les modèles séquentiels comme les RNN et leurs variantes dominaient le traitement des données temporelles et textuelles, mais leur structure linéaire limitait la capture des dépendances distantes.L’attention a bouleversé cette logique en permettant au modèle de pondérer dynamiquement l’importance de chaque élément d’une séquence selon le contexte global. Ce changement de paradigme a offert une flexibilité nouvelle, capable de gérer simultanément des relations locales et globales, tout en améliorant la précision dans la compréhension du sens et des nuances sémantiques.
Sur le plan computationnel, cette innovation a également introduit une efficacité remarquable. En supprimant la contrainte séquentielle, les calculs peuvent être parallélisés, ce qui accélère considérablement l’entraînement des modèles sur de grands corpus.
Cette capacité à combiner puissance, rapidité et contextualisation a ouvert la voie à une nouvelle génération d’architectures. Il s'agit des Transformers qui reposent entièrement sur le principe d’attention. Depuis l’article fondateur "Attention Is All You Need", ces modèles ont révolutionné le traitement du langage naturel, la vision artificielle et bien d’autres domaines en devenant le socle des systèmes modernes comme BERT, GPT ou T5.
Je vous invite à découvrir ce short d’une minute qui explique brièvement le mécanisme d’attention:
Leçon 17
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Limites des RNN face au vanishing gradient et aux dépendances longues: apports des LSTM et GRU
Leçon 22
Le mécanisme d'attention et la résolution des limites des RNN
Le mécanisme d'attention et la résolution des limites des RNN


