Natural Language Processing (NLP) - Fondements et applications






Leçon 18: Word Embedding: comprendre le langage grâce aux vecteurs sémantiques
Toutes les leçons 
Natural Language Processing (NLP) - Fondements et applications
Leçon 18
Word Embedding: comprendre le langage grâce aux vecteurs sémantiques
Word Embedding: comprendre le langage grâce aux vecteurs sémantiques
Word Embedding - Capturer la sémantiques des mots
Du comptage à la compréhension: l’évolution vers les word embeddings
Le Bag of Words (BoW) et le TF‑IDF sont des représentations textuelles basées sur la fréquence des mots. BoW consiste à transformer un texte en vecteur où chaque dimension correspond à un mot du vocabulaire, avec comme valeur le nombre d’occurrences. TF‑IDF affine cette approche en pondérant les mots selon leur importance locale (fréquence dans le document) et globale (rareté dans le corpus). Ces méthodes sont simples et efficaces pour certaines tâches, mais elles présentent des limites majeures. En effet, elles produisent des vecteurs très longs et clairsemés, ignorent l’ordre des mots et surtout ne capturent pas la sémantique. Ainsi, deux mots synonymes comme voiture et automobile seront représentés par des vecteurs totalement différents, sans lien entre eux.Les word embeddings viennent dépasser ces limites en proposant une représentation dense et continue des mots dans un espace vectoriel. Chaque mot est associé à un vecteur de dimension réduite (souvent 100 à 300), appris à partir du contexte dans lequel il apparaît. L’idée est que les mots ayant des significations proches auront des vecteurs proches. Cela permet de réaliser des opérations sémantiques étonnantes. Par exemple, dans un modèle Word2Vec, on peut obtenir l’analogie Paris – France + Italie ≈ Rome. Autrement dit, le vecteur de Paris est à France ce que le vecteur de Rome est à talie.
Cette capacité à capturer les relations entre les mots rend les embeddings beaucoup plus puissants pour les tâches de NLP modernes, allant de la classification de texte à la traduction automatique.
Word Embedding - Concrètement, ça donne quoi?
Concrètement, le résultat d’un word embedding est une matrice dense où chaque ligne correspond à un mot du vocabulaire et chaque colonne à une dimension du vecteur associé. Si l’on choisit une dimension de 300, chaque mot est représenté par un vecteur de 300 valeurs réelles. Cette matrice est donc beaucoup plus compacte que celles issues de BoW ou TF‑IDF, qui sont très grandes et clairsemées.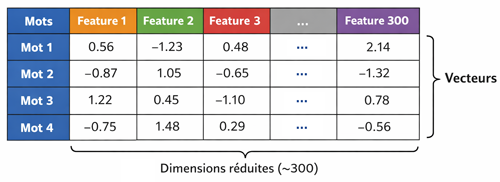
Les dimensions peuvent être vues comme des caractéristiques latentes des mots. Par exemple, une dimension peut refléter à quel point un mot est associé à l’humain (homme, femme, enfant), une autre peut capturer la notion de rapidité (voiture, avion, rapide), une autre encore peut représenter la dimension géographique (Paris, Rome, Italie). Ces caractéristiques ne sont pas définies explicitement par l’humain, mais apprises automatiquement par le modèle à partir des contextes d’utilisation des mots. C’est cette capacité à condenser et révéler des traits sémantiques implicites qui rend les embeddings si puissants pour le NLP moderne.
Les grandes familles de Word Embedding
Word2Vec (Google, 2013)
Word2Vec, développé par Google en 2013, est une méthode de word embedding qui apprend des vecteurs de mots à partir de leur contexte. Elle permet de capturer efficacement des relations sémantiques et analogies remarquables.Word2vec utilise deux architectures pour construire les embeddings, à savoir CBOW et Skip‑Gram:
- CBOW (Continuous Bag of Words): cette approche prédit un mot cible à partir de son contexte. Par exemple, si la phrase est "Paris est la capitale de la France", le modèle prend les mots autour de France (comme "Paris", "capitale") et apprend à prédire "France". CBOW est efficace sur de grands corpus et rapide à entraîner car il exploite directement les co‑occurrences locales.
- Skip‑Gram: ici, c’est l’inverse, c'est à dire que le modèle prend un mot cible et apprend à prédire les mots du contexte. Dans la même phrase, si le mot cible est "France", le modèle doit prédire les mots voisins ("Paris", "capitale"). Skip‑Gram est particulièrement performant pour capturer des relations sémantiques fines même avec des mots rares.
Grâce à ces deux architectures, Word2Vec apprend des vecteurs capables de réaliser des analogies sémantiques. L’exemple classique est: Paris – France + Italie ≈ Rome. Cela montre que les vecteurs encodent non seulement la proximité des mots, mais aussi leurs relations conceptuelles (ici, capitale et pays).
GloVe (Stanford, 2014)
GloVe (Global Vectors for Word Representation), développé par l’université de Stanford en 2014, est une méthode de word embedding qui combine deux approches:- Statistiques globales: elle exploite les co‑occurrences de mots dans l’ensemble du corpus, en construisant une matrice qui capture combien de fois les mots apparaissent ensemble.
- Contexte local: elle intègre également l’information des mots voisins dans les phrases, ce qui permet de conserver la richesse du contexte immédiat.
Le modèle apprend ainsi des vecteurs où les distances reflètent les relations sémantiques et syntaxiques. Par exemple, les vecteurs de "Paris" et "France" seront proches, tout comme ceux de "Rome" et "Italie". Cela permet de réaliser des analogies similaires à Word2Vec, mais en s’appuyant sur une base statistique plus robuste.
GloVe a été entraîné sur de très grands corpus publics comme Wikipedia et Gigaword qui est une base de données composée d’articles de presse issus de différentes agences, ce qui apporte une richesse linguistique et une grande variété de contextes.
GloVe est disponible sous forme de modèles pré‑entraînés que l’on peut directement télécharger et utiliser sans avoir à réentraîner soi‑même sur un corpus. Ces embeddings sont proposés en différentes tailles de vecteurs (50, 100, 200 et 300 dimensions).
FastText (Facebook, 2016)
FastText, développé par Facebook en 2016, est une évolution de Word2Vec qui enrichit la représentation des mots en les décomposant en sous‑mots (n‑grammes de caractères). Plutôt que d’attribuer un vecteur unique à chaque mot, FastText construit le vecteur final comme la somme des vecteurs de ses sous‑unités. Par exemple, le mot "jouer" peut être représenté par les fragments "jou", "oue", "uer", ce qui permet au modèle de capturer la structure interne du mot.Cette approche présente deux avantages majeurs: elle gère mieux les mots rares ou inconnus, car leurs sous‑mots apparaissent souvent ailleurs dans le corpus, et elle s’adapte parfaitement aux langues morphologiquement riches où les variations de conjugaison ou de déclinaison sont nombreuses.
En pratique, FastText produit des embeddings plus robustes et plus généralisables que Word2Vec, tout en conservant la capacité à exprimer des analogies sémantiques.
BERT (Google, 2018)
BERT (Bidirectional Encoder Representations from Transformers), introduit par Google en 2018, marque une avancée majeure dans le domaine du NLP grâce aux embeddings contextuels.Contrairement à Word2Vec ou GloVe, qui attribuent un vecteur fixe à chaque mot, BERT génère une représentation qui dépend de la phrase entière. Ainsi, le mot "banque" n’aura pas le même vecteur dans "banque de données" et "banque financière", car le modèle tient compte du contexte global.
Cette capacité provient de son architecture basée sur les Transformers, qui utilisent des mécanismes d’attention bidirectionnelle. BERT lit simultanément à gauche et à droite du mot cible, ce qui lui permet de comprendre les relations complexes entre les mots.
En pratique, cela améliore considérablement les performances sur des tâches comme la classification de texte, la reconnaissance d’entités nommées ou la réponse à des questions. BERT est donc considéré comme une étape clé vers une compréhension fine et nuancée du langage naturel.
Exemple pratique de calcul des embeddings
En utilisant Word2Vec
Je propose cet exemple simple:from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
corpus = [
"Le chat dort sur le canapé",
"Le chien joue dans le jardin",
"Le renard saute par-dessus la clôture",
"Les oiseaux volent haut dans le ciel"
]
tokenized_corpus = [
word_tokenize(phrase.lower()) for phrase in corpus
]
# Entraîner le modèle Word2Vec
model = Word2Vec(
sentences=tokenized_corpus,
vector_size=100,
window=5,
min_count=1,
workers=4
)
# Obtenir le vecteur du mot "chat"
print(model.wv["chat"].round(4))
Ce petit script montre comment entraîner rapidement un modèle Word2Vec avec la bibliothèque gensim à partir d’un corpus simple.
from nltk.tokenize import word_tokenize
corpus = [
"Le chat dort sur le canapé",
"Le chien joue dans le jardin",
"Le renard saute par-dessus la clôture",
"Les oiseaux volent haut dans le ciel"
]
tokenized_corpus = [
word_tokenize(phrase.lower()) for phrase in corpus
]
# Entraîner le modèle Word2Vec
model = Word2Vec(
sentences=tokenized_corpus,
vector_size=100,
window=5,
min_count=1,
workers=4
)
# Obtenir le vecteur du mot "chat"
print(model.wv["chat"].round(4))
Les phrases sont d’abord tokenisées avec nltk pour obtenir une liste de mots en minuscules. Ensuite, le modèle est entraîné avec des paramètres comme la taille des vecteurs (100 dimensions), la fenêtre de contexte (5 mots), et le seuil minimal d’occurrence (min_count=1). Une fois l’entraînement terminé, on interroge le modèle pour obtenir le vecteur associé au mot "chat", ce qui donne ce résultat:
[ 0.0097 -0.0098 -0.0065 0.0028 0.0064 -0.0054 0.0028 0.0091 -0.0068
-0.0061 -0.005 -0.0037 0.0018 0.0097 0.0064 0.0004 0.0025 0.0084
0.0091 0.0056 0.0059 -0.0076 -0.0038 -0.0057 0.0062 -0.0023 -0.0088
0.0076 0.0084 -0.0033 0.0091 -0.0007 -0.0036 -0.0004 0.0002 -0.0035
0.0028 0.0057 0.0069 -0.0089 -0.0022 -0.0055 0.0075 0.0065 -0.0044
0.0023 -0.006 0.0002 0.0095 -0.0026 -0.0052 -0.0074 -0.0029 -0.0009
0.0035 0.0097 -0.0034 0.0019 0.0097 0.0015 0.001 0.0098 0.0093
0.0077 -0.0062 0.01 0.0058 0.0091 -0.002 0.0033 0.0068 -0.0039
0.0066 0.0026 0.0093 -0.003 -0.0031 0.0062 -0.0091 -0.0073 -0.0065
-0.0007 -0.0024 0.0068 0.0092 -0.0009 0.0014 0.002 -0.002 -0.008
0.0074 -0.0043 0.0046 0.0091 0.003 0.0031 0.0041 -0.0027 0.0038
0.0003]
Par défaut, dans gensim, le modèle Word2Vec utilise l’architecture CBOW (paramètre sg=0). Si l’on souhaite entraîner le modèle avec l’architecture Skip‑Gram, il suffit d’ajouter le paramètre sg=1 lors de l’initialisation.
-0.0061 -0.005 -0.0037 0.0018 0.0097 0.0064 0.0004 0.0025 0.0084
0.0091 0.0056 0.0059 -0.0076 -0.0038 -0.0057 0.0062 -0.0023 -0.0088
0.0076 0.0084 -0.0033 0.0091 -0.0007 -0.0036 -0.0004 0.0002 -0.0035
0.0028 0.0057 0.0069 -0.0089 -0.0022 -0.0055 0.0075 0.0065 -0.0044
0.0023 -0.006 0.0002 0.0095 -0.0026 -0.0052 -0.0074 -0.0029 -0.0009
0.0035 0.0097 -0.0034 0.0019 0.0097 0.0015 0.001 0.0098 0.0093
0.0077 -0.0062 0.01 0.0058 0.0091 -0.002 0.0033 0.0068 -0.0039
0.0066 0.0026 0.0093 -0.003 -0.0031 0.0062 -0.0091 -0.0073 -0.0065
-0.0007 -0.0024 0.0068 0.0092 -0.0009 0.0014 0.002 -0.002 -0.008
0.0074 -0.0043 0.0046 0.0091 0.003 0.0031 0.0041 -0.0027 0.0038
0.0003]
Gensim est une bibliothèque Python spécialisée dans le NLP et l’apprentissage automatique non supervisé. Elle est particulièrement connue pour ses implémentations efficaces de modèles de word embedding comme Word2Vec, FastText ou Doc2Vec. Elle permet de manipuler de grands corpus textuels de manière simple et rapide tout en offrant une interface haut niveau pour entraîner, charger et utiliser des modèles pré‑entraînés.
En utilisant FastText
Le principe est le même en utilisant la bibliothèque gensim:from gensim.models import FastText
from nltk.tokenize import word_tokenize
corpus = [
"Le chat dort sur le canapé",
"Le chien joue dans le jardin",
"Le renard saute par-dessus la clôture",
"Les oiseaux volent haut dans le ciel"
]
tokenized_corpus = [
word_tokenize(phrase.lower()) for phrase in corpus
]
# Entraîner le modèle FastText
model = FastText(
sentences=tokenized_corpus,
vector_size=100,
window=5,
min_count=1,
workers=4,
sg=1
)
# Obtenir le vecteur du mot "chat"
print(model.wv["chat"].round(4))
Cette fois, nous avons entrainé le modèle en utilisat Skip-Gram (sg=1). Ce qui produit ce résultat:
from nltk.tokenize import word_tokenize
corpus = [
"Le chat dort sur le canapé",
"Le chien joue dans le jardin",
"Le renard saute par-dessus la clôture",
"Les oiseaux volent haut dans le ciel"
]
tokenized_corpus = [
word_tokenize(phrase.lower()) for phrase in corpus
]
# Entraîner le modèle FastText
model = FastText(
sentences=tokenized_corpus,
vector_size=100,
window=5,
min_count=1,
workers=4,
sg=1
)
# Obtenir le vecteur du mot "chat"
print(model.wv["chat"].round(4))
[ 9.0e-04 1.3e-03 -1.7e-03 -1.3e-03 2.6e-03 -6.0e-04 1.1e-03 3.8e-03
-1.0e-04 1.4e-03 -0.0e+00 -2.7e-03 -2.6e-03 2.3e-03 2.3e-03 1.1e-03
-2.1e-03 0.0e+00 -2.8e-03 -2.1e-03 -1.6e-03 3.0e-03 -1.4e-03 1.1e-03
5.0e-04 -1.6e-03 -4.2e-03 2.4e-03 1.2e-03 1.7e-03 2.9e-03 8.0e-04
1.1e-03 -1.7e-03 2.4e-03 1.7e-03 6.0e-04 -0.0e+00 2.0e-04 -1.1e-03
-5.0e-04 -1.5e-03 -7.0e-04 -7.0e-04 -5.0e-04 2.5e-03 5.0e-04 1.4e-03
-2.5e-03 -8.0e-04 -1.7e-03 -1.6e-03 -0.0e+00 -1.2e-03 -1.3e-03 -0.0e+00
-1.4e-03 4.0e-04 2.4e-03 -1.0e-04 1.0e-04 2.6e-03 1.2e-03 -1.0e-03
2.0e-03 2.9e-03 -1.6e-03 -2.6e-03 -2.0e-04 1.4e-03 1.0e-04 -1.5e-03
-1.9e-03 4.0e-04 -4.0e-04 -1.8e-03 4.0e-04 2.0e-03 -4.0e-04 -1.0e-04
-1.9e-03 -1.0e-03 -2.2e-03 2.0e-03 5.0e-04 7.0e-04 3.0e-04 -0.0e+00
7.0e-04 -1.1e-03 9.0e-04 1.9e-03 -3.0e-04 2.4e-03 -7.0e-04 -3.8e-03
2.1e-03 2.0e-04 3.3e-03 8.0e-04]
-1.0e-04 1.4e-03 -0.0e+00 -2.7e-03 -2.6e-03 2.3e-03 2.3e-03 1.1e-03
-2.1e-03 0.0e+00 -2.8e-03 -2.1e-03 -1.6e-03 3.0e-03 -1.4e-03 1.1e-03
5.0e-04 -1.6e-03 -4.2e-03 2.4e-03 1.2e-03 1.7e-03 2.9e-03 8.0e-04
1.1e-03 -1.7e-03 2.4e-03 1.7e-03 6.0e-04 -0.0e+00 2.0e-04 -1.1e-03
-5.0e-04 -1.5e-03 -7.0e-04 -7.0e-04 -5.0e-04 2.5e-03 5.0e-04 1.4e-03
-2.5e-03 -8.0e-04 -1.7e-03 -1.6e-03 -0.0e+00 -1.2e-03 -1.3e-03 -0.0e+00
-1.4e-03 4.0e-04 2.4e-03 -1.0e-04 1.0e-04 2.6e-03 1.2e-03 -1.0e-03
2.0e-03 2.9e-03 -1.6e-03 -2.6e-03 -2.0e-04 1.4e-03 1.0e-04 -1.5e-03
-1.9e-03 4.0e-04 -4.0e-04 -1.8e-03 4.0e-04 2.0e-03 -4.0e-04 -1.0e-04
-1.9e-03 -1.0e-03 -2.2e-03 2.0e-03 5.0e-04 7.0e-04 3.0e-04 -0.0e+00
7.0e-04 -1.1e-03 9.0e-04 1.9e-03 -3.0e-04 2.4e-03 -7.0e-04 -3.8e-03
2.1e-03 2.0e-04 3.3e-03 8.0e-04]
Dans les exemples traités, le corpus utilisé est volontairement très réduit et donc pauvre en occurrences. Cela permet d’illustrer le fonctionnement de Word2Vec et FastText, mais en pratique, un modèle d’embedding n’est pertinent que lorsqu’il est entraîné sur un corpus volumineux et varié (millions de phrases ou plus).
Leçon 18
Word Embedding: comprendre le langage grâce aux vecteurs sémantiques
Word Embedding: comprendre le langage grâce aux vecteurs sémantiques


