Natural Language Processing (NLP) - Fondements et applications






Leçon 14: Analyse de cooccurrence: étape clé de l'EDA en NLP exploratoire
Toutes les leçons 
Natural Language Processing (NLP) - Fondements et applications
Leçon 14
Analyse de cooccurrence: étape clé de l'EDA en NLP exploratoire
Analyse de cooccurrence: étape clé de l'EDA en NLP exploratoire
Analyse de cooccurrence en NLP
Qu'est ce que l'analyse de cooccurrence et quelle est son utilité en NLP?
L’analyse de cooccurrence consiste à étudier la fréquence avec laquelle deux mots apparaissent ensemble dans un même contexte. Contrairement aux simples statistiques de fréquence, elle révèle les relations lexicales et les collocations, c’est-à-dire des associations de mots qui forment des unités de sens.Par exemple, dans un corpus sur l’intelligence artificielle, les mots intelligence et artificielle apparaissent souvent côte à côte, ce qui traduit une association forte et significative.
L'utilité de l'analyse de cooccurrenceest multiple:
- Elle permet de détecter des expressions figées ou des termes techniques récurrents, essentiels pour comprendre le vocabulaire d’un domaine.
- Elle aide à identifier des thématiques en repérant des groupes de mots qui coapparaissent fréquemment, ce qui facilite la segmentation d’un corpus en sujets cohérents.
- Elle constitue une base pour les modèles de plongement lexical (Word2Vec, GloVe), qui exploitent directement les cooccurrences pour apprendre des représentations vectorielles des mots.
- Enfin, elle offre une lecture stylistique d’un texte ou d’un auteur, en mettant en lumière les associations privilégiées dans un corpus littéraire ou scientifique.
En EDA, cette étape enrichit considérablement l’exploration: elle ne se limite pas à dire quels mots sont fréquents, mais montre comment ils interagissent entre eux, ouvrant la voie à une compréhension plus fine des structures linguistiques et thématiques.
Méthodes de calcul de la cooccurrence
Matrice de cooccurrence
On peut construire une matrice de cooccurrence où chaque ligne et chaque colonne correspondent à un mot du vocabulaire. Les cellules indiquent alors le nombre de fois où deux mots apparaissent ensemble dans le corpus. Cette représentation est particulièrement adaptée aux corpus de taille réduite car elle permet de visualiser directement les associations lexicales et de repérer rapidement les relations les plus fortes entre les termes.Fenêtre glissante (sliding window)
On définit une taille de fenêtre (par exemple 5 mots) autour de chaque terme du corpus. À chaque occurrence d’un mot, on observe les mots voisins présents dans cette fenêtre et on incrémente leurs cooccurrences.Ce procédé permet de capturer les associations locales et plus la fenêtre est réduite, plus les liens détectés sont forts et précis, car ils traduisent une proximité lexicale immédiate plutôt qu’une simple co‑présence dans un texte plus large.
Mesures statistiques
Pour dépasser le simple comptage des cooccurrences, il est utile d’introduire des mesures statistiques qui évaluent la force réelle des associations entre mots. Par exemple:- PMI (Pointwise Mutual Information): cette mesure compare la probabilité conjointe de deux termes avec leurs probabilités individuelles, ce qui permet de mettre en avant les associations réellement significatives plutôt que celles dues au hasard.
- Chi² ou log-likelihood: ces tests statistiques servent à mesurer la robustesse de l’association entre deux mots et à vérifier si leur cooccurrence est suffisamment forte pour être considérée comme pertinente dans l’analyse.
Ainsi, l’usage de ces indicateurs enrichit l’EDA en NLP en distinguant les relations lexicales importantes des simples cooccurrences accidentelles.
Visualisations de la cooccurrence
Graphes de cooccurrence
Dans une représentation graphique des cooccurrences, les mots sont figurés comme des nœuds, tandis que les cooccurrences sont traduites par des arêtes pondérées reliant ces nœuds. Plus la pondération est élevée, plus la relation entre les mots est forte. Ce type de graphe est particulièrement utile car il met en évidence des clusters thématiques, c’est-à-dire des groupes de mots qui apparaissent fréquemment ensemble, et rend visible la structure lexicale d’un corpus. En un coup d’œil, on peut ainsi identifier les associations dominantes, les sous-thèmes émergents et la manière dont le vocabulaire s’organise autour de concepts centraux.Des bibliothèques comme networkx ou des outils comme Gephi permettent de générer ces visualisations.
Carte thermique (Heatmap)
La matrice de cooccurrence peut être représentée sous forme de carte thermique (heatmap), où l’intensité des couleurs traduit la force des associations entre mots.Cette visualisation rend immédiatement perceptibles les couples de termes les plus liés, facilitant ainsi l’identification rapide des relations lexicales dominantes dans le corpus.
Mise en pratique de l'analyse de cooccurrence
Visualisation de la cooccurrence à travers une carte thermique
Je propose ce code:import nltk
from nltk import word_tokenize
from nltk.util import ngrams
from collections import Counter
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
texte = """L'intelligence artificielle tente de rédoudre
des problèmes sans écrire de programmes explicites.
L'intelligence artificielle pourrait bien nous
simplifier la vie."""
mots = word_tokenize(texte.lower())
# Génération des bigrammes
bigrammes = list(ngrams(mots, 2))
frequences = Counter(bigrammes)
# Bigrammes les plus fréquents (par ex. top 8)
top_bigrammes = frequences.most_common(8)
# Extraire le vocabulaire
vocabulaire_reduit = sorted(set(
[mot for bigramme, _ in top_bigrammes for mot in bigramme]
))
# Création d'une matrice réduite
matrice = pd.DataFrame(
0, index=vocabulaire_reduit, columns=vocabulaire_reduit
)
for (mot1, mot2), freq in top_bigrammes:
matrice.loc[mot1, mot2] = freq
matrice.loc[mot2, mot1] = freq # symétrie
# Visualisation en heatmap
plt.figure(figsize=(6,5))
sns.heatmap(matrice, cmap="Blues", annot=True, fmt="d")
plt.show()
L'exécution du code produit l'illustration suivante:
from nltk import word_tokenize
from nltk.util import ngrams
from collections import Counter
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
texte = """L'intelligence artificielle tente de rédoudre
des problèmes sans écrire de programmes explicites.
L'intelligence artificielle pourrait bien nous
simplifier la vie."""
mots = word_tokenize(texte.lower())
# Génération des bigrammes
bigrammes = list(ngrams(mots, 2))
frequences = Counter(bigrammes)
# Bigrammes les plus fréquents (par ex. top 8)
top_bigrammes = frequences.most_common(8)
# Extraire le vocabulaire
vocabulaire_reduit = sorted(set(
[mot for bigramme, _ in top_bigrammes for mot in bigramme]
))
# Création d'une matrice réduite
matrice = pd.DataFrame(
0, index=vocabulaire_reduit, columns=vocabulaire_reduit
)
for (mot1, mot2), freq in top_bigrammes:
matrice.loc[mot1, mot2] = freq
matrice.loc[mot2, mot1] = freq # symétrie
# Visualisation en heatmap
plt.figure(figsize=(6,5))
sns.heatmap(matrice, cmap="Blues", annot=True, fmt="d")
plt.show()
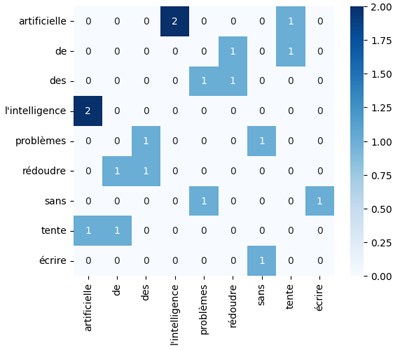
Le code présenté est suffisamment clair et lisible pour un lecteur familier avec Python et NLTK. Donc, je suppose qu'il n'est pas nécessaire de détailler chaque ligne. L’essentiel est de comprendre la logique générale (tokenisation → génération de bigrammes → comptage → visualisation).
Leçon 14
Analyse de cooccurrence: étape clé de l'EDA en NLP exploratoire
Analyse de cooccurrence: étape clé de l'EDA en NLP exploratoire


