Natural Language Processing (NLP) - Fondements et applications






Leçon 20: Analyse de sentiments avec un réseau LSTM: Classification multi-classes des tweets
Toutes les leçons 
Natural Language Processing (NLP) - Fondements et applications
Leçon 20
Analyse de sentiments avec un réseau LSTM: Classification multi-classes des tweets
Analyse de sentiments avec un réseau LSTM: Classification multi-classes des tweets
Réseaux récurrents pour l’analyse de sentiments: application aux compagnies aériennes
Approche Deep Learning pour la classification multi‑classes en analyse de sentiments
Dans ce projet, nous allors appliquer un réseau de neurones récurrent de type LSTM à l’analyse de sentiments sur le corpus US Airline Sentiment constitué de milliers de tweets annotés en trois classes (négatif, neutre, positif). Après un prétraitement des données (tokenisation et padding des séquences), nous allons construire un modèle séquentiel intégrant une couche d’embedding pour représenter les mots, suivie d’une couche LSTM afin de capturer les dépendances temporelles du langage, et enfin une couche de sortie softmax pour la classification multi-classes.Le modèle sera entraîné sur un jeu d’apprentissage et évalué sur un jeu de test, permettant de mesurer la précision et les scores F1 par classe (en plus des métriques traditionnelles liées à la classification).
Je rappelle que nous avons déjà abordé l’analyse de sentiments sur ce même dataset US Airline Sentiment en utilisant l’approche lexicale VADER. Cette première méthode reposait sur des règles et des scores de polarité prédéfinis, tandis que le présent travail illustre une approche Deep Learning avec réseaux LSTM permettant de comparer les performances et les limites des deux techniques.
Construction d'un réseau LSTM pour l'analsye de sentiments
Comme nous avons l'habitude de procéder, je vais vous donner le code en une seule fois, puis je m'arrêterai sur les points qui nécessitent plus de détails:import pandas as pd
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Input, LSTM, Dense
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from tensorflow.keras.callbacks import EarlyStopping
import matplotlib.pyplot as plt
data=pd.read_csv("US_Tweets.csv")
data=data[["text","airline_sentiment"]].head(10000)
data["airline_sentiment"]=data["airline_sentiment"].map(
{"negative":0,"neutral":1,"positive":2}
)
tokenizer = Tokenizer(num_words=5000)
tokenizer.fit_on_texts(data["text"])
sequences = tokenizer.texts_to_sequences(data["text"])
max_length = 10
X = pad_sequences(
sequences,
maxlen=max_length,
padding='post'
)
y=data["airline_sentiment"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
early_stop = EarlyStopping(
monitor="val_loss",
patience=3,
restore_best_weights=True
)
model = Sequential([
Input(shape=(max_length,)),
Embedding(input_dim=5000, output_dim=16),
LSTM(64, return_sequences=False),
Dense(3, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
model.build(input_shape=(None, max_length))
model.summary()
history=model.fit(
X_train, y_train,
epochs=10, batch_size=2,
validation_split=0.2,
callbacks=[early_stop]
)
y_pred=model.predict(X_test).argmax(axis=1)
print(classification_report(y_test,y_pred))
plt.plot(history.history["loss"],c="b", label="Loss")
plt.plot(history.history["val_loss"],c="r", label="Val Loss")
plt.legend()
plt.show()
Passons aux explications:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Input, LSTM, Dense
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from tensorflow.keras.callbacks import EarlyStopping
import matplotlib.pyplot as plt
data=pd.read_csv("US_Tweets.csv")
data=data[["text","airline_sentiment"]].head(10000)
data["airline_sentiment"]=data["airline_sentiment"].map(
{"negative":0,"neutral":1,"positive":2}
)
tokenizer = Tokenizer(num_words=5000)
tokenizer.fit_on_texts(data["text"])
sequences = tokenizer.texts_to_sequences(data["text"])
max_length = 10
X = pad_sequences(
sequences,
maxlen=max_length,
padding='post'
)
y=data["airline_sentiment"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
early_stop = EarlyStopping(
monitor="val_loss",
patience=3,
restore_best_weights=True
)
model = Sequential([
Input(shape=(max_length,)),
Embedding(input_dim=5000, output_dim=16),
LSTM(64, return_sequences=False),
Dense(3, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
model.build(input_shape=(None, max_length))
model.summary()
history=model.fit(
X_train, y_train,
epochs=10, batch_size=2,
validation_split=0.2,
callbacks=[early_stop]
)
y_pred=model.predict(X_test).argmax(axis=1)
print(classification_report(y_test,y_pred))
plt.plot(history.history["loss"],c="b", label="Loss")
plt.plot(history.history["val_loss"],c="r", label="Val Loss")
plt.legend()
plt.show()
Dans ce projet, nous combinons plusieurs outils essentiels pour l’analyse de sentiments avec Deep Learning:
import pandas as pd
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Input, LSTM, Dense
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from tensorflow.keras.callbacks import EarlyStopping
import matplotlib.pyplot as plt
En effet, Pandas est utilisé pour charger et manipuler le dataset, tandis que TensorFlow/Keras fournit les briques nécessaires à la construction du modèle séquentiel (couche Embedding pour représenter les mots, LSTM pour capturer les dépendances temporelles et Dense pour la classification). Le module Tokenizer et la fonction pad_sequences assurent la préparation des textes en séquences numériques de longueur fixe. Scikit‑learn intervient pour séparer les données en ensembles d’entraînement et de test ainsi que pour générer des métriques via classification_report. Enfin, le callback EarlyStopping de Keras permet de contrôler l’entraînement en arrêtant automatiquement le processus si la performance de validation cesse de s’améliorer évitant ainsi le sur‑apprentissage.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Input, LSTM, Dense
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from tensorflow.keras.callbacks import EarlyStopping
import matplotlib.pyplot as plt
On sélectionne uniquement les colonnes text et airline_sentiment du DataFrame, puis limite l’échantillon aux 10000 premières lignes afin de travailler sur un sous‑ensemble représentatif du dataset:
data=data[["text","airline_sentiment"]].head(10000)
Ensuite, on transforme les étiquettes textuelles de sentiments (negative, neutral, positive) en valeurs numériques (0, 1, 2) afin de rendre les classes exploitables par les algorithmes de Deep Learning:
data["airline_sentiment"]=data["airline_sentiment"].map(
{"negative":0,"neutral":1,"positive":2}
)
La prochaine étape consiste à la tokenisation et la création du vocabulaire:
{"negative":0,"neutral":1,"positive":2}
)
tokenizer = Tokenizer(num_words=5000)
tokenizer.fit_on_texts(data["text"])
sequences = tokenizer.texts_to_sequences(data["text"])
max_length = 10
X = pad_sequences(
sequences,
maxlen=max_length,
padding='post'
)
y=data["airline_sentiment"]
Après avoir transformé les textes en séquences numériques grâce au Tokenizer, chaque phrase se retrouve représentée par une liste d’indices correspondant aux mots du vocabulaire. Or, ces séquences ont des longueurs variables selon la taille des phrases, ce qui pose problème pour l’entrée dans un réseau de neurones qui attend des vecteurs de dimension fixe. La fonction pad_sequences permet de résoudre cette contrainte en uniformisant toutes les séquences à une longueur maximale définie (max_length). Les séquences trop courtes sont complétées par des zéros (padding), tandis que les séquences trop longues sont tronquées. Ainsi, on obtient une matrice homogène de taille (nombre d’exemples, max_length) parfaitement adaptée à l’entrée du modèle LSTM.
tokenizer.fit_on_texts(data["text"])
sequences = tokenizer.texts_to_sequences(data["text"])
max_length = 10
X = pad_sequences(
sequences,
maxlen=max_length,
padding='post'
)
y=data["airline_sentiment"]
La tokenisation utilisée ici est une tokenisation au niveau des mots où chaque terme du corpus est associé à un indice numérique en fonction de sa fréquence. Les phrases sont ainsi converties en séquences d’entiers, puis uniformisées grâce à pad_sequences pour obtenir des vecteurs de longueur fixe.
Ensuite, on définit une stratégie d’arrêt anticipé qui surveille la perte de validation et interrompt l’entraînement si elle ne s’améliore plus après 3 epochs afin de prévenir l'overfitting, tout en restaurant automatiquement les meilleurs poids obtenus:
early_stop = EarlyStopping(
monitor="val_loss",
patience=3,
restore_best_weights=True
)
On sépare les données d'entrainement des données de test:
monitor="val_loss",
patience=3,
restore_best_weights=True
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
L’argument stratify=y garantit que la séparation en train et test conserve la même proportion de classes (négatif, neutre, positif) que dans le dataset original, évitant ainsi un déséquilibre artificiel entre les sous‑ensembles.
X, y, test_size=0.2, random_state=42, stratify=y
)
On constuit ensuite notre modèle:
model = Sequential([
Input(shape=(max_length,)),
Embedding(input_dim=5000, output_dim=16),
LSTM(64, return_sequences=False),
Dense(3, activation='softmax')
])
Le modèle défini est un réseau séquentiel composé de quatre couches principales. Une couche Input fixe la dimension des séquences en entrée (max_length). La couche Embedding transforme ensuite les indices de mots en vecteurs continus de dimension 16, permettant une meilleure représentation sémantique du texte. La couche LSTM avec 64 unités capture les dépendances temporelles et contextuelles entre les mots d’une phrase. Enfin, une couche Dense avec activation softmax produit une sortie à trois neurones correspondant aux classes de sentiments (négatif, neutre, positif).
Input(shape=(max_length,)),
Embedding(input_dim=5000, output_dim=16),
LSTM(64, return_sequences=False),
Dense(3, activation='softmax')
])
On compile notre modèle:
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
model.build(input_shape=(None, max_length))
model.summary()
Le modèle est compilé avec l’optimiseur Adam, une fonction de perte sparse_categorical_crossentropy adaptée à la classification multi‑classes, et l’indicateur de performance accuracy.
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
model.build(input_shape=(None, max_length))
model.summary()
L’appel à model.build(input_shape=(None, max_length)) initialise explicitement les poids et dimensions internes du réseau pour des séquences de longueur max_length. Enfin, model.summary() fournit un résumé détaillé de l’architecture, affichant les couches, le nombre de paramètres et les dimensions de sortie, ce qui permet de vérifier la cohérence du modèle avant l’entraînement.
Sans l’appel explicite à model.build(...), les dimensions et les poids du réseau ne sont pas créés immédiatement; ils ne seront initialisés automatiquement qu’au moment du premier entraînement ou lors du passage de données.
La prochaine étape consiste à lancer l’entraînement du modèle sur les données d’apprentissage pendant 10 epochs, avec des mini‑lots de taille 2 en réservant 20% des données pour la validation, et en appliquant la stratégie d’arrêt anticipé (EarlyStopping) pour éviter l'overfitting.
history=model.fit(
X_train, y_train,
epochs=10, batch_size=2,
validation_split=0.2,
callbacks=[early_stop]
)
X_train, y_train,
epochs=10, batch_size=2,
validation_split=0.2,
callbacks=[early_stop]
)
Après, on génère les prédictions du modèle sur l’ensemble de test, puis on sélectionne pour chaque exemple la classe la plus probable en prenant l’indice du maximum sur l’axe des colonnes:
y_pred=model.predict(X_test).argmax(axis=1)
En fin de processus, on évalue les performances du modèle avec classification_report qui fournit les métriques de précision, rappel et F1‑score pour chaque classe, puis on trace la courbe d’apprentissage afin de visualiser l’évolution de la perte et de l’accuracy au fil des epochs:
print(classification_report(y_test,y_pred))
plt.plot(history.history["loss"],c="b", label="Loss")
plt.plot(history.history["val_loss"],c="r", label="Val Loss")
plt.legend()
plt.show()
Après exécution du code on obtient le rapport de classification suivant:
plt.plot(history.history["loss"],c="b", label="Loss")
plt.plot(history.history["val_loss"],c="r", label="Val Loss")
plt.legend()
plt.show()
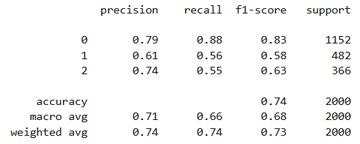
Le modèle atteint une accuracy globale de 0.74, ce qui traduit une performance correcte. La classe 0 (négatif) est la mieux reconnue avec un F1‑score de 0.83 grâce à un bon équilibre entre précision et rappel. En revanche, la classe 1 (neutre) reste la plus difficile à prédire (F1‑score de 0.58), ce qui suggère une confusion fréquente avec les autres sentiments. La classe 2 (positif) obtient un score intermédiaire (F1‑score de 0.63), avec une précision correcte mais un rappel limité.
La learning curve obtenu ressemble à ceci:
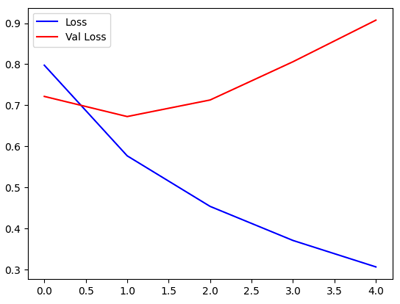
La courbe d’apprentissage montre que la val_loss commence à augmenter dès la deuxième époque. Grâce au mécanisme d’EarlyStopping, l’entraînement s’interrompt automatiquement plus tôt (après 5 époques) afin d’éviter le sur‑apprentissage et de conserver les meilleurs poids du modèle, alors que l’entraînement était prévu pour 10 époques.
Leçon 20
Analyse de sentiments avec un réseau LSTM: Classification multi-classes des tweets
Analyse de sentiments avec un réseau LSTM: Classification multi-classes des tweets


