Natural Language Processing (NLP) - Fondements et applications






Leçon 17: TF-IDF: pondérer l'importance des mots pour mieux représenter le texte
Toutes les leçons 
Natural Language Processing (NLP) - Fondements et applications
Leçon 17
TF-IDF: pondérer l'importance des mots pour mieux représenter le texte
TF-IDF: pondérer l'importance des mots pour mieux représenter le texte
Term Frequency - Inverse Document Frequency (TF-IDF)
De BoW à TF‑IDF: dépasser les limites des fréquences brutes
Le modèle Bag of Words (BoW), bien qu’utile pour représenter un texte sous forme vectorielle, présente des limites importantes. En effet, il considère uniquement la fréquence brute des mots sans tenir compte de leur importance relative ni du contexte. Ainsi, un mot très fréquent comme "le" ou "et" peut dominer la représentation, alors qu’il n’apporte que peu de valeur sémantique. De plus, BoW ne distingue pas entre des mots rares mais significatifs et des mots courants peu informatifs. C'est pour pallier ces limites que l’on utilise la méthode TF‑IDF.TF‑IDF (Term Frequency - Inverse Document Frequency) combine deux mesures: la fréquence d’un mot dans un document (TF) et son importance inverse dans l’ensemble du corpus (IDF). Concrètement, TF‑IDF réduit le poids des mots trop fréquents et met en avant ceux qui sont plus discriminants. Cette pondération permet d’obtenir une représentation plus pertinente du contenu textuel largement utilisée en recherche d’information, en classification de documents et dans les moteurs de recherche pour améliorer la pertinence des résultats.
Vecteur TF‑IDF: réduire le bruit et valoriser l’information
Contrairement au modèle Bag of Words (BoW) qui produit une matrice souvent très large et peu informative (chaque mot est représenté par sa fréquence brute, ce qui génère beaucoup de colonnes redondantes), le modèle TF‑IDF aboutit à une matrice plus réduite et pertinente. En effet, la pondération par l’IDF diminue fortement l’impact des mots trop fréquents et peu discriminants, ce qui revient à "nettoyer" la représentation vectorielle.La matrice obtenue après l’application du TF‑IDF se présente ainsi:
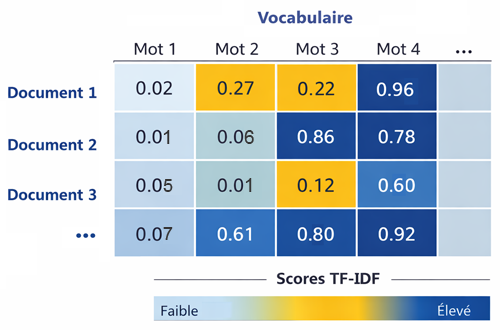
Ainsi, la matrice TF‑IDF conserve les dimensions liées aux termes du vocabulaire, mais les coefficients attribués aux mots courants deviennent proches de zéro. Le résultat est une représentation plus compacte, où seuls les mots réellement porteurs d’information gardent un poids significatif. Cette réduction améliore non seulement l’efficacité des algorithmes de classification ou de recherche, mais elle rend aussi la matrice plus exploitable en pratique, comparée à la densité brute produite par BoW.
Cas d'usage: de la détection de mots‑clés aux systèmes de recommandation
Voici quelques exemples d’applications de TF‑IDF:- Moteurs de recherche: TF‑IDF est utilisé pour évaluer la pertinence d’un document par rapport à une requête. Les mots rares mais significatifs reçoivent un poids plus élevé, ce qui améliore la qualité des résultats affichés.
- Classification de documents: En transformant les textes en vecteurs pondérés, TF‑IDF permet aux algorithmes de machine learning (comme SVM ou k‑NN) de mieux distinguer les catégories de documents.
- Détection de mots‑clés: TF‑IDF aide à extraire automatiquement les termes les plus représentatifs d’un texte, ce qui est utile pour le résumé automatique ou l’indexation.
- Filtrage de spam: Les emails peuvent être représentés par des vecteurs TF‑IDF, ce qui permet de repérer des mots caractéristiques du spam et d’améliorer la détection.
- Systèmes de recommandation: En analysant les descriptions ou contenus textuels avec TF‑IDF, on peut rapprocher des documents ou produits similaires et proposer des recommandations plus pertinentes.
La formule de calcul du TF‑IDF
Le calcul du TF‑IDF repose sur deux étapes fondamentales:- TF (Term Frequency): il mesure la fréquence d’apparition d’un terme \(t\) dans un document \(d\). La formule la plus courante est:
\(TF(t,d)=\frac{f_{t,d}}{N_d}\)où \(f_{t,d}\) est le nombre d’occurrences du terme \(t\) dans le document \(d\), et \(N_d\) le nombre total de mots du document.
- IDF (Inverse Document Frequency): il évalue l’importance d’un terme en fonction de sa rareté dans le corpus. La formule est généralement:
\(IDF(t)=\log \left( \frac{N}{n_t}\right) \)où \(N\) est le nombre total de documents du corpus et \(n_t\) le nombre de documents contenant le terme \(t\).
La pondération finale est obtenue par:
\(TF\mathrm{-}IDF(t,d)=TF(t,d)\times IDF(t)\)
Ainsi, un mot fréquent dans un document mais rare dans le corpus obtient un score élevé, tandis qu’un mot très courant dans tous les documents voit son poids réduit, ce qui rend la représentation vectorielle plus discriminante et exploitable.
Exemple d'application de TF-IDF
Identifier les termes significatifs d’un corpus par rapport aux documents
Je propose ce code qui illustre une application simple de TF‑IDF avec scikit‑learn:from sklearn.feature_extraction.text
import TfidfVectorizer
documents = [
"le jour le ciel est bleu",
"le ciel est noir la nuit",
"Les étoiles rendent le ciel plus beau la nuit"
]
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(documents)
print(tfidf_matrix.toarray().round(2))
print(vectorizer.get_feature_names_out())
On commence par définir une petite liste de documents textuels (documents). Ensuite, on crée un objet TfidfVectorizer qui va transformer ces documents en une matrice TF‑IDF: chaque ligne correspond à un document et chaque colonne à un mot du vocabulaire extrait.
import TfidfVectorizer
documents = [
"le jour le ciel est bleu",
"le ciel est noir la nuit",
"Les étoiles rendent le ciel plus beau la nuit"
]
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(documents)
print(tfidf_matrix.toarray().round(2))
print(vectorizer.get_feature_names_out())
La méthode fit_transform calcule directement les pondérations TF‑IDF pour chaque mot dans chaque document.
L’instruction print(tfidf_matrix.toarray().round(2)) affiche la matrice sous forme de tableau numérique arrondi à deux décimales ce qui permet de voir les poids attribués aux mots.
Enfin, vectorizer.get_feature_names_out() liste les termes du vocabulaire retenus, c’est‑à‑dire les colonnes de la matrice.
L'exécution du code produit ce résultat:
[[0. 0.48 0.28 0.37 0.48 0. 0.57 0. 0. 0. 0. 0. 0. ]
[0. 0. 0.32 0.41 0. 0.41 0.32 0. 0.54 0.41 0. 0. 0. ]
[0.38 0. 0.23 0. 0. 0.29 0.23 0.38 0. 0.29 0.38 0.38 0.38]]
['beau' 'bleu' 'ciel' 'est' 'jour' 'la' 'le' 'les' 'noir' 'nuit' 'plus' 'rendent' 'étoiles']
Si on prent le Document 2 ("le ciel est noir la nuit"), le mot "nuit" a le score le plus élevé (0.54), car il est spécifique à ce document et rare dans le corpus, ce qui lui donne un poids fort.
[0. 0. 0.32 0.41 0. 0.41 0.32 0. 0.54 0.41 0. 0. 0. ]
[0.38 0. 0.23 0. 0. 0.29 0.23 0.38 0. 0.29 0.38 0.38 0.38]]
['beau' 'bleu' 'ciel' 'est' 'jour' 'la' 'le' 'les' 'noir' 'nuit' 'plus' 'rendent' 'étoiles']
Leçon 17
TF-IDF: pondérer l'importance des mots pour mieux représenter le texte
TF-IDF: pondérer l'importance des mots pour mieux représenter le texte
: une approche basique d'extraction de caractéristiques en NLP")

