Preprocessing et Feature Engineering: booster les performances d'un modèle IA






Leçon 3: Preprocessing par imputation: renforcer la qualité des datasets incomplets
Toutes les leçons 
Preprocessing et Feature Engineering: booster les performances d'un modèle IA
Leçon 3
Preprocessing par imputation: renforcer la qualité des datasets incomplets
Preprocessing par imputation: renforcer la qualité des datasets incomplets
Imputation des données manquantes: une alternative à la perte d’information
De la suppression à l’imputation: préserver l’intégrité du dataset
Lorsqu’on rencontre des données manquantes, une première approche consiste à les supprimer (soit en retirant les lignes concernées, soit en éliminant les variables trop incomplètes). Cette solution est simple mais elle présente un inconvénient majeur. En effet, elle réduit la taille du dataset, ce qui peut entraîner une perte d’information précieuse et biaiser les résultats. Plus la proportion de données supprimées est importante, plus le modèle risque de perdre en représentativité et en capacité de généralisation surtout si les valeurs manquantes ne sont pas réparties de manière aléatoire comme on l'a vu dans la leçon consacrée au nettoyage de données par suppression. Pour éviter cette perte, on recourt à l’imputation.L’imputation désigne le processus par lequel les valeurs manquantes sont remplacées par des estimations jugées cohérentes. Cette approche permet de conserver l’ensemble des observations et de réduire l’effet négatif des données incomplètes sur l’analyse. Elle peut s’appuyer sur des méthodes simples comme l’utilisation de la moyenne, la médiane ou le mode, mais aussi sur des techniques plus avancées comme les modèles prédictifs ou les algorithmes de voisinage comme le KNN.
Cette étape est cruciale car elle permet de préserver la richesse du dataset et d’améliorer la robustesse des modèles. En imputant correctement, on réduit le biais lié à la suppression, on maintient la cohérence statistique et on donne aux algorithmes de machine learning une base plus complète pour apprendre. En résumé, l’imputation est une stratégie qui équilibre la nécessité de traiter les données manquantes avec le souci de ne pas sacrifier l’information disponible.
Imputation simple des données du dataset Titanic
Nous allons reprendre le dataset Titanic afin d’illustrer différentes techniques d’imputation simple des données manquantes, à savoir la moyenne, la médiane et le mode (c’est‑à‑dire la valeur la plus fréquente). Je présenterai le code complet en une seule fois, puis je reviendrai sur les points essentiels pour en expliquer le fonctionnement:import pandas as pd
from sklearn.impute import SimpleImputer
df = pd.read_csv("titanic.csv")
#### Exemple d'imputation sur des variables numériques
# Moyenne
imputer_mean = SimpleImputer(strategy="mean")
df["Age_mean"] = imputer_mean.fit_transform(df[["Age"]])
# Médiane
imputer_median = SimpleImputer(strategy="median")
df["Age_median"] = imputer_median.fit_transform(df[["Age"]])
#### Exemple d'imputation sur une variable catégorielle
# Mode (valeur la plus fréquente)
imputer_mode = SimpleImputer(strategy="most_frequent")
df["Embarked_mode"] = imputer_mode.fit_transform(df[["Embarked"]])[:,0]
# Vérification des 20 premiers enregistrements après l'imputation
df[["Age", "Age_mean", "Age_median", "Embarked", "Embarked_mode"]].head(20)
Après avoir importé la classe SimpleImputer du module sklearn.impute, on crée un objet imputer_mean qui va remplacer les valeurs manquantes par la moyenne de la colonne voulue dans le dataset en spécifiant la stratégie "mean":
from sklearn.impute import SimpleImputer
df = pd.read_csv("titanic.csv")
#### Exemple d'imputation sur des variables numériques
# Moyenne
imputer_mean = SimpleImputer(strategy="mean")
df["Age_mean"] = imputer_mean.fit_transform(df[["Age"]])
# Médiane
imputer_median = SimpleImputer(strategy="median")
df["Age_median"] = imputer_median.fit_transform(df[["Age"]])
#### Exemple d'imputation sur une variable catégorielle
# Mode (valeur la plus fréquente)
imputer_mode = SimpleImputer(strategy="most_frequent")
df["Embarked_mode"] = imputer_mode.fit_transform(df[["Embarked"]])[:,0]
# Vérification des 20 premiers enregistrements après l'imputation
df[["Age", "Age_mean", "Age_median", "Embarked", "Embarked_mode"]].head(20)
imputer_mean = SimpleImputer(strategy="mean")
La méthode fit_transform() calcule la moyenne de la colonne "Age" et remplace les valeurs manquantes par cette moyenne.
Le résultat est stocké dans une nouvelle colonne "Age_mean" du DataFrame df:
df["Age_mean"] = imputer_mean.fit_transform(df[["Age"]])
En gros, ce code crée une nouvelle colonne avec les valeurs d'âge complétées (les valeurs manquantes sont remplacées par la moyenne de la colonne).
Que fait la méthode fit_transform()?
La méthode fit_transform() est une méthode couramment utilisée dans les bibliothèques de machine learning, en l'occurrence Scikit-learn. Elle combine deux étapes importantes:- fit() : Elle ajuste le modèle aux données d'entraînement, c'est-à-dire qu'elle calcule les paramètres nécessaires (comme la moyenne et l'écart-type pour la normalisation, ou dans ce cas, la moyenne de la colonne "Age" pour remplacer les valeurs manquantes).
- transform(): Elle applique la transformation aux données (comme la normalisation, la réduction de dimension, ou ici, le remplacement des valeurs manquantes par la moyenne calculée).
Donc, fit_transform() fait les deux en même temps: elle calcule dabord la moyenne de la colonne "Age" à l'aide de la méthode implicite fit(), puis remplace les valeurs manquantes par cette moyenne à l'aide de la méthode transform().
La méthode fit_transform() est pratique pour les données d'entraînement. Pour les données de test, on utilise généralement juste transform() pour appliquer les mêmes transformations (par exemple, remplacer les valeurs manquantes par la même moyenne calculée sur les données d'entraînement).
On procède de la même manière pour générer les colones "Age_median" et "Embarked_mode". On change seulement la stratégie d'imputation (respectivement strategy="median" et strategy="most_frequent").
Pour les variables catégorielles, la stratégie strategy="most_frequent" (qui sous entend le mode) avec SimpleImputer est souvent privilégiée car elle permet de remplacer les valeurs manquantes par la catégorie la plus fréquente, ce qui est logique et cohérent avec la nature des données catégorielles. Cette approche évite également d'introduire des valeurs numériques qui n'ont pas de sens pour une variable catégorielle, contrairement aux stratégies mean ou median qui sont plus adaptées aux variables numériques. En effet, remplacer une valeur manquante par la catégorie la plus fréquente permet de minimiser l'impact sur la distribution des données et de préserver la cohérence de la variable, ce qui est particulièrement important pour les algorithmes de machine learning qui pourraient être sensibles aux valeurs aberrantes ou aux distributions biaisées.
dans l'instruction:
df["Embarked_mode"] = imputer_mode.fit_transform(df[["Embarked"]])[:,0],
[:, 0] est utilisé pour extraire la première (et unique) colonne du résultat de fit_transform(), qui renvoie un tableau 2D. En effet, fit_transform() sur une colonne (df[["Embarked"]]) renvoie un tableau de forme (n, 1), où n est le nombre de lignes. En ajoutant [:, 0], on transforme ce tableau 2D en un tableau 1D (une simple Series), ce qui est plus adapté pour être stocké dans une colonne de DataFrame (df["Embarked_mode"]). En fait, dans le cas d’Age, pandas devine qu'on veut convertir le tableau 2D en 1D et le fait à notre place.
A la fin, on affiche un aperçu des données transformées (avec les données originale) en nous limitant aux cinq enregistrements situés entre les positions 15 et 19 (cette plage contient deux valeurs manquantes dans la colone Age):
df["Embarked_mode"] = imputer_mode.fit_transform(df[["Embarked"]])[:,0],
[:, 0] est utilisé pour extraire la première (et unique) colonne du résultat de fit_transform(), qui renvoie un tableau 2D. En effet, fit_transform() sur une colonne (df[["Embarked"]]) renvoie un tableau de forme (n, 1), où n est le nombre de lignes. En ajoutant [:, 0], on transforme ce tableau 2D en un tableau 1D (une simple Series), ce qui est plus adapté pour être stocké dans une colonne de DataFrame (df["Embarked_mode"]). En fait, dans le cas d’Age, pandas devine qu'on veut convertir le tableau 2D en 1D et le fait à notre place.
df[["Age", "Age_mean", "Age_median", "Embarked", "Embarked_mode"]].iloc[15:20].head()
On aura donc ce résultat:
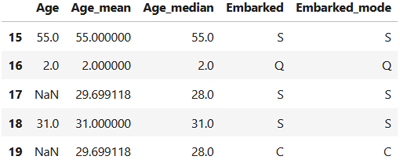
On constate que les valeurs manquantes dans la colone "Age" (NaN) ont été remplacées par la moyenne (29.699118) et la médiane (28.0). Concerant les valeurs manquantes dans la colone "Embarked" qui contient des valeurs catégorielles, elles seront certainement remplacées par la valeur la plus fréquente "S".
Imputation fondée sur les k plus proches voisins (k-NN)
L’imputation par k plus proches voisins (k‑NN) consiste à remplacer une valeur manquante par la moyenne des valeurs observées chez les individus les plus similaires. Au lieu d’utiliser une statistique globale comme la moyenne ou la médiane, K‑NN recherche d’abord les k lignes les plus proches selon les autres variables disponibles, puis calcule une valeur imputée basée sur ces voisins.L'approche de l'imputation par k-NN est plus "contextuelle". En effet, elle tient compte de la structure réelle des données et permet d’obtenir des valeurs imputées plus cohérentes, surtout lorsque les variables sont corrélées entre elles. En revanche, elle ne peut s’appliquer qu’à des variables numériques, car le calcul de distance entre individus nécessite des valeurs continues.
Comparée aux méthodes simples (moyenne, médiane, mode), l’imputation K‑NN présente un avantage majeur. En effet, elle évite d’aplatir la variabilité naturelle des données. La moyenne et la médiane donnent la même valeur à tous les individus manquants, ce qui peut introduire des biais et réduire la dispersion. Le mode quant à lui, peut sur‑représenter une catégorie dominante. Par contre, l'impuatation par K‑NN produit des valeurs différentes selon le profil de chaque individu, ce qui préserve mieux la distribution et les relations entre variables. C’est une méthode plus réaliste, surtout dans des jeux de données riches, mais elle demande plus de calcul et une préparation adéquate des variables utilisées pour mesurer la similarité.
Appliquons l'imputation par K-NN à notre jeu de donnée:
import pandas as pd
from sklearn.impute import KNNImputer
df = pd.read_csv("titanic.csv")
# Colonnes numériques utiles pour la similarité
cols = ["Age", "Pclass", "Fare", "SibSp", "Parch"]
# Imputation KNN
imputer_knn = KNNImputer(n_neighbors=5)
df_knn = imputer_knn.fit_transform(df[cols])
# La première colonne correspond à Age imputé
df["Age_knn"] = df_knn[:, 0]
# Vérification
df[["Age", "Age_knn"]].iloc[15:20].head()
On a préparé une liste de colonnes numériques qui serviront à mesurer la similarité entre les individus.
from sklearn.impute import KNNImputer
df = pd.read_csv("titanic.csv")
# Colonnes numériques utiles pour la similarité
cols = ["Age", "Pclass", "Fare", "SibSp", "Parch"]
# Imputation KNN
imputer_knn = KNNImputer(n_neighbors=5)
df_knn = imputer_knn.fit_transform(df[cols])
# La première colonne correspond à Age imputé
df["Age_knn"] = df_knn[:, 0]
# Vérification
df[["Age", "Age_knn"]].iloc[15:20].head()
# Colonnes numériques utiles pour la similarité
cols = ["Age", "Pclass", "Fare", "SibSp", "Parch"]
Ces variables (l’âge, la classe du billet, le tarif payé et la composition familiale) permettent au KNNImputer d’identifier les passagers les plus proches les uns des autres.
cols = ["Age", "Pclass", "Fare", "SibSp", "Parch"]
Ensuite, on crée un imputer K‑NN avec 5 voisins et on l’applique sur ces colonnes:
# Imputation KNN
imputer_knn = KNNImputer(n_neighbors=5)
df_knn = imputer_knn.fit_transform(df[cols])
Le modèle calcule pour chaque valeur manquante, la moyenne des valeurs observées chez les 5 passagers les plus similaires, ce qui produit une imputation plus cohérente que les méthodes simples.
imputer_knn = KNNImputer(n_neighbors=5)
df_knn = imputer_knn.fit_transform(df[cols])
En affichant les enregistrements situés entre les positions 15 et 20 on obtient:
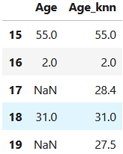
On peut identifier deux valeurs différentes appliquées lors de l'imputation des valeurs manquantes concernant l'âge des passagers.
Cette méthode reste toutefois limitée aux variables numériques, car le calcul de distance utilisé par K‑NN repose sur des mesures continues permettant d’évaluer la proximité entre individus. Pour comparer deux exemples, l’algorithme doit pouvoir mesurer des écarts (différences, distances euclidiennes, moyennes des voisins), ce qui n’est possible que lorsque les valeurs sont représentées sous forme numérique.
Leçon 3
Preprocessing par imputation: renforcer la qualité des datasets incomplets
Preprocessing par imputation: renforcer la qualité des datasets incomplets


